第九章 高级线程管理
第九章 高级线程管理
在并发编程中,显式管理线程可能并不理想,因为需要处理线程对象的生命周期和确定线程数量等问题。
理想的情况是,能够将代码划分为可并发执行的最小片段,并让编译器和库自动管理线程和任务的并行化,以达到最优性能。
此外,当需要在满足某些条件时提前结束线程时,需要有一种机制来向线程发送停止请求,以便它们能够整理并尽快完成。
线程池
线程池(Thread Pool)是一种软件设计模式,用于实现计算机编程中的并发执行。它也经常被称为复制工人或工人队模型(replicated workers or worker-crew mode)。
线程池维护多个线程,等待被监督程序分配任务以进行并发执行。
它的主要目标是通过重复利用已创建的线程来降低线程创建和销毁造成的消耗。
这种模式类似于公司的汽车池,员工可以根据需要使用汽车,而不是每个员工都拥有一辆汽车。
线程池的主要优点包括:
- 通过复用已存在的线程,降低创建和销毁线程的消耗。
- 任务到达时,可以不需要等待线程的创建立即执行,从而提高响应速度。
- 线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,因此,需要使用线程池来管理线程。
线程池的工作原理主要包括:
- 如果当前运行的线程数量少于核心线程池的大小,则会创建新的线程来执行新的任务;
- 如果运行的线程数量等于或者大于核心线程池的大小,则会将提交的任务存放到阻塞队列中;
- 如果当前阻塞队列已满,并且线程池的线程数量没有超过最大线程池的大小,则会创建新的线程来执行任务;
- 如果线程池的线程数量已经超过了最大线程池的大小,并且阻塞队列已满,则会使用饱和策略来进行处理。
The simplest possible thread pool
线程池一般会用一个表示线程数的参数来初始化,内部需要一个队列来存储任务。下面是一个最简单的线程池实现
// Simple thread pool
#include <vector>
#include <queue>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <functional>
class ThreadPool {
public:
ThreadPool(size_t numThreads) {
// 创建n个工作线程并存在本地的工作线程中
for (size_t i = 0; i < numThreads; ++i) {
workers.emplace_back([this] {
while (true) {
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(this->queueMutex);
this->condition.wait(lock, [this] { return this->stop || !this->tasks.empty(); });
// 当线程池状态Stop为true退出所有执行线程
if (this->stop && this->tasks.empty()) return;
// 激活的线程继续执行任务
task = std::move(this->tasks.front());
this->tasks.pop();
}
task();
}
});
}
}
template<class F>
void enqueue(F&& f) {
{
std::unique_lock<std::mutex> lock(queueMutex);
// don't allow enqueueing after stopping the pool
if (stop) throw std::runtime_error("enqueue on stopped ThreadPool");
tasks.emplace(std::forward<F>(f));
}
condition.notify_one();
}
~ThreadPool() {
{
std::unique_lock<std::mutex> lock(queueMutex);
stop = true; // wait 使用了 strop 判断所以要加锁
}
condition.notify_all();
for (std::thread &worker: workers) worker.join();
}
private:
std::vector<std::thread> workers;
std::queue<std::function<void()>> tasks;
std::mutex queueMutex;
std::condition_variable condition;
bool stop = false;
};
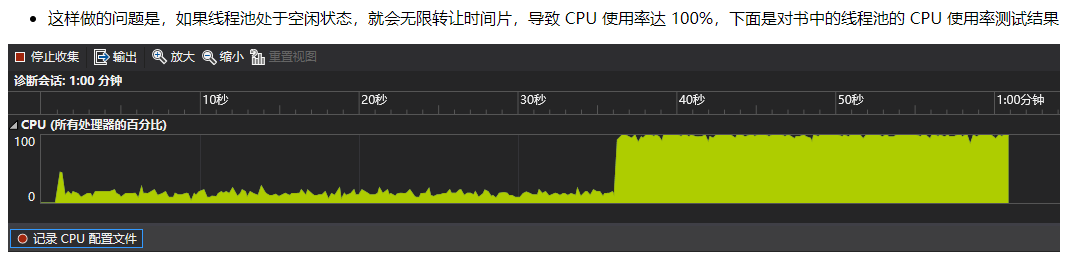
书上实现的线程池都在死循环中使用了 stdyield 来转让时间片, 这会带来一些问题
// sample
#include <atomic>
#include <functional>
#include <thread>
#include <vector>
#include "concurrent_queue.hpp"
class ThreadPool {
public:
ThreadPool() {
std::size_t n = std::thread::hardware_concurrency();
try {
for (std::size_t i = 0; i < n; ++i) {
threads_.emplace_back(&ThreadPool::worker_thread, this);
}
} catch (...) {
done_ = true;
for (auto& x : threads_) {
if (x.joinable()) {
x.join();
}
}
throw;
}
}
~ThreadPool() {
done_ = true;
for (auto& x : threads_) {
if (x.joinable()) {
x.join();
}
}
}
template <typename F>
void submit(F f) {
q_.push(std::function<void()>(f));
}
private:
void worker_thread() {
while (!done_) {
std::function<void()> task;
if (q_.try_pop(task)) {
task();
} else {
std::this_thread::yield();
}
}
}
private:
std::atomic<bool> done_ = false;
ConcurrentQueue<std::function<void()>> q_;
std::vector<std::thread> threads_; // 要在 done_ 和 q_ 之后声明
};
Waiting for tasks submitted to a thread pool
function_wrapper类是一个函数包装器,它可以存储任何可调用对象(例如函数、lambda表达式或函数对象),并提供一个统一的调用接口。
这个类使用了类型擦除技术,通过一个内部的基类impl_base和一个模板子类impl_type来实现。impl_base定义了一个纯虚函数call(),impl_type则重写了这个函数,使其调用存储的可调用对象。function_wrapper类还重载了函数调用操作符operator(),使得我们可以像调用普通函数一样调用function_wrapper对象, 如下:
// FunctionWrapper
#include <memory>
#include <utility>
class FunctionWrapper {
public:
FunctionWrapper() = default;
FunctionWrapper(const FunctionWrapper&) = delete;
FunctionWrapper& operator=(const FunctionWrapper&) = delete;
FunctionWrapper(FunctionWrapper&& rhs) noexcept
: impl_(std::move(rhs.impl_)) {}
FunctionWrapper& operator=(FunctionWrapper&& rhs) noexcept {
impl_ = std::move(rhs.impl_);
return *this;
}
template <typename F>
FunctionWrapper(F&& f) : impl_(new ImplType<F>(std::move(f))) {}
void operator()() const { impl_->call(); }
private:
struct ImplBase {
virtual void call() = 0;
virtual ~ImplBase() = default;
};
template <typename F>
struct ImplType : ImplBase {
ImplType(F&& f) noexcept : f_(std::move(f)) {}
void call() override { f_(); }
F f_;
};
private:
std::unique_ptr<ImplBase> impl_;
};
- 用这个包裹类替代
std::function<void()>
// sample
#include <atomic>
#include <future>
#include <thread>
#include <type_traits>
#include <vector>
#include "concurrent_queue.hpp"
#include "function_wrapper.hpp"
class ThreadPool {
public:
ThreadPool() {
std::size_t n = std::thread::hardware_concurrency();
try {
for (std::size_t i = 0; i < n; ++i) {
threads_.emplace_back(&ThreadPool::worker_thread, this);
}
} catch (...) {
done_ = true;
for (auto& x : threads_) {
if (x.joinable()) {
x.join();
}
}
throw;
}
}
~ThreadPool() {
done_ = true;
for (auto& x : threads_) {
if (x.joinable()) {
x.join();
}
}
}
template <typename F>
std::future<std::invoke_result_t<F>> submit(F f) {
std::packaged_task<std::invoke_result_t<F>()> task(std::move(f));
std::future<std::invoke_result_t<F>> res(task.get_future());
q_.push(std::move(task));
return res;
}
private:
void worker_thread() {
while (!done_) {
FunctionWrapper task;
if (q_.try_pop(task)) {
task();
} else {
std::this_thread::yield();
}
}
}
private:
std::atomic<bool> done_ = false;
ConcurrentQueue<FunctionWrapper> q_;
std::vector<std::thread> threads_; // 要在 done_ 和 q_ 之后声明
};
Avoiding contention on the work queue
往线程池添加任务会增加任务队列的竞争,lock-free 队列可以避免这点但存在乒乓缓存的问题。为此需要把任务队列拆分为线程独立的本地队列和全局队列,当线程队列无任务时就去全局队列取任务。
// sample
#include <atomic>
#include <future>
#include <memory>
#include <queue>
#include <thread>
#include <type_traits>
#include <vector>
#include "concurrent_queue.hpp"
#include "function_wrapper.hpp"
class ThreadPool {
public:
ThreadPool() {
std::size_t n = std::thread::hardware_concurrency();
try {
for (std::size_t i = 0; i < n; ++i) {
threads_.emplace_back(&ThreadPool::worker_thread, this);
}
} catch (...) {
done_ = true;
for (auto& x : threads_) {
if (x.joinable()) {
x.join();
}
}
throw;
}
}
~ThreadPool() {
done_ = true;
for (auto& x : threads_) {
if (x.joinable()) {
x.join();
}
}
}
template <typename F>
std::future<std::invoke_result_t<F>> submit(F f) {
std::packaged_task<std::invoke_result_t<F>()> task(std::move(f));
std::future<std::invoke_result_t<F>> res(task.get_future());
if (local_queue_) {
local_queue_->push(std::move(task));
} else {
pool_queue_.push(std::move(task));
}
return res;
}
private:
void worker_thread() {
local_queue_.reset(new std::queue<FunctionWrapper>);
while (!done_) {
FunctionWrapper task;
if (local_queue_ && !local_queue_->empty()) {
task = std::move(local_queue_->front());
local_queue_->pop();
task();
} else if (pool_queue_.try_pop(task)) {
task();
} else {
std::this_thread::yield();
}
}
}
private:
std::atomic<bool> done_ = false;
ConcurrentQueue<FunctionWrapper> pool_queue_;
inline static thread_local std::unique_ptr<std::queue<FunctionWrapper>>
local_queue_;
std::vector<std::thread> threads_;
};
Work stealing
为了让没有工作要做的线程能够从队列满的其他线程中窃取工作,队列必须对执行run_pending_tasks()的线程可访问。这需要每个线程将其队列注册到线程池,或者由线程池提供一个队列。此外,你还必须确保工作队列中的数据适当地同步和保护,以保护不变量。
// sample
#include <atomic>
#include <deque>
#include <future>
#include <memory>
#include <mutex>
#include <thread>
#include <type_traits>
#include <vector>
#include "concurrent_queue.hpp"
#include "function_wrapper.hpp"
class WorkStealingQueue {
public:
WorkStealingQueue() = default;
WorkStealingQueue(const WorkStealingQueue&) = delete;
WorkStealingQueue& operator=(const WorkStealingQueue&) = delete;
void push(FunctionWrapper f) {
std::lock_guard<std::mutex> l(m_);
q_.push_front(std::move(f));
}
bool empty() const {
std::lock_guard<std::mutex> l(m_);
return q_.empty();
}
bool try_pop(FunctionWrapper& res) {
std::lock_guard<std::mutex> l(m_);
if (q_.empty()) {
return false;
}
res = std::move(q_.front());
q_.pop_front();
return true;
}
bool try_steal(FunctionWrapper& res) {
std::lock_guard<std::mutex> l(m_);
if (q_.empty()) {
return false;
}
res = std::move(q_.back());
q_.pop_back();
return true;
}
private:
std::deque<FunctionWrapper> q_;
mutable std::mutex m_;
};
class ThreadPool {
public:
ThreadPool() {
std::size_t n = std::thread::hardware_concurrency();
try {
for (std::size_t i = 0; i < n; ++i) {
work_stealing_queue_.emplace_back(
std::make_unique<WorkStealingQueue>());
threads_.emplace_back(&ThreadPool::worker_thread, this, i);
}
} catch (...) {
done_ = true;
for (auto& x : threads_) {
if (x.joinable()) {
x.join();
}
}
throw;
}
}
~ThreadPool() {
done_ = true;
for (auto& x : threads_) {
if (x.joinable()) {
x.join();
}
}
}
template <typename F>
std::future<std::invoke_result_t<F>> submit(F f) {
std::packaged_task<std::invoke_result_t<F>()> task(std::move(f));
std::future<std::invoke_result_t<F>> res(task.get_future());
if (local_queue_) {
local_queue_->push(std::move(task));
} else {
pool_queue_.push(std::move(task));
}
return res;
}
private:
bool pop_task_from_local_queue(FunctionWrapper& task) {
return local_queue_ && local_queue_->try_pop(task);
}
bool pop_task_from_pool_queue(FunctionWrapper& task) {
return pool_queue_.try_pop(task);
}
bool pop_task_from_other_thread_queue(FunctionWrapper& task) {
for (std::size_t i = 0; i < work_stealing_queue_.size(); ++i) {
std::size_t index = (index_ + i + 1) % work_stealing_queue_.size();
if (work_stealing_queue_[index]->try_steal(task)) {
return true;
}
}
return false;
}
void worker_thread(std::size_t index) {
index_ = index;
local_queue_ = work_stealing_queue_[index_].get();
while (!done_) {
FunctionWrapper task;
if (pop_task_from_local_queue(task) || pop_task_from_pool_queue(task) ||
pop_task_from_other_thread_queue(task)) {
task();
} else {
std::this_thread::yield();
}
}
}
private:
std::atomic<bool> done_ = false;
ConcurrentQueue<FunctionWrapper> pool_queue_;
std::vector<std::unique_ptr<WorkStealingQueue>> work_stealing_queue_;
std::vector<std::thread> threads_;
static thread_local WorkStealingQueue* local_queue_;
static thread_local std::size_t index_;
};
thread_local WorkStealingQueue* ThreadPool::local_queue_;
thread_local std::size_t ThreadPool::index_;
线程中断
线程中断是一种在多线程编程中常见的概念。当一个线程正在执行任务时,我们可能需要在某个时刻停止这个线程的执行。
这种情况可能是因为线程池正在被销毁,或者用户明确取消了线程正在执行的任务,等等。无论原因是什么,我们都需要一种机制来从一个线程向另一个线程发送停止信号。
然而,C++11标准并没有提供一个内置的机制来中断线程。但是,你可以使用std::atomic<bool>或std::condition_variable来设计自己的机制。
// std::atomic<bool>
#include <atomic>
#include <thread>
#include <iostream>
std::atomic<bool> stopFlag(false);
void workerThread() {
while (!stopFlag) {
// Do some work...
std::cout << "Working...\n";
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}
int main() {
std::thread worker(workerThread);
// Let the worker thread run for a while...
std::this_thread::sleep_for(std::chrono::seconds(5));
// Signal the worker thread to stop...
stopFlag = true;
// Wait for the worker thread to finish...
worker.join();
return 0;
}
// std::condition_variable
class InterruptFlag {
public:
void set() {
b_.store(true, std::memory_order_relaxed);
std::lock_guard<std::mutex> l(m_);
if (cv_) {
cv_->notify_all();
}
}
bool is_set() const { return b_.load(std::memory_order_relaxed); }
void set_condition_variable(std::condition_variable& cv) {
std::lock_guard<std::mutex> l(m_);
cv_ = &cv;
}
void clear_condition_variable() {
std::lock_guard<std::mutex> l(m_);
cv_ = nullptr;
}
struct ClearConditionVariableOnDestruct {
~ClearConditionVariableOnDestruct() {
this_thread_interrupt_flag.clear_condition_variable();
}
};
private:
std::atomic<bool> b_;
std::condition_variable* cv_ = nullptr;
std::mutex m_;
};
void interruptible_wait(std::condition_variable& cv,
std::unique_lock<std::mutex>& l) {
interruption_point();
this_thread_interrupt_flag.set_condition_variable(cv);
// 之后的 wait_for 可能抛异常,所以需要 RAII 清除标志
InterruptFlag::ClearConditionVariableOnDestruct guard;
interruption_point();
// 设置线程看到中断前的等待时间上限
cv.wait_for(l, std::chrono::milliseconds(1));
interruption_point();
}
template <typename Predicate>
void interruptible_wait(std::condition_variable& cv,
std::unique_lock<std::mutex>& l, Predicate pred) {
interruption_point();
this_thread_interrupt_flag.set_condition_variable(cv);
InterruptFlag::ClearConditionVariableOnDestruct guard;
while (!this_thread_interrupt_flag.is_set() && !pred()) {
cv.wait_for(l, std::chrono::milliseconds(1));
}
interruption_point();
}
和 stdcondition_variable_any 可以使用不限于 std::unique_lock 的任何类型的锁,这意味着可以使用自定义的锁类型
// sample
#include <atomic>
#include <condition_variable>
#include <mutex>
class InterruptFlag {
public:
void set() {
b_.store(true, std::memory_order_relaxed);
std::lock_guard<std::mutex> l(m_);
if (cv_) {
cv_->notify_all();
} else if (cv_any_) {
cv_any_->notify_all();
}
}
template <typename Lockable>
void wait(std::condition_variable_any& cv, Lockable& l) {
class Mutex {
public:
Mutex(InterruptFlag* self, std::condition_variable_any& cv, Lockable& l)
: self_(self), lock_(l) {
self_->m_.lock();
self_->cv_any_ = &cv;
}
~Mutex() {
self_->cv_any_ = nullptr;
self_->m_.unlock();
}
void lock() { std::lock(self_->m_, lock_); }
void unlock() {
lock_.unlock();
self_->m_.unlock();
}
private:
InterruptFlag* self_;
Lockable& lock_;
};
Mutex m(this, cv, l);
interruption_point();
cv.wait(m);
interruption_point();
}
// rest as before
private:
std::atomic<bool> b_;
std::condition_variable* cv_ = nullptr;
std::condition_variable_any* cv_any_ = nullptr;
std::mutex m_;
};
template <typename Lockable>
void interruptible_wait(std::condition_variable_any& cv, Lockable& l) {
this_thread_interrupt_flag.wait(cv, l);
}
对于其他阻塞调用(比如 mutex、future)的中断,一般也可以像对 std::condition_variable 一样设置超时时间,因为不访问内部 mutex 或 future 无法在未满足等待的条件时中断等待
// sample
template <typename T>
void interruptible_wait(std::future<T>& ft) {
while (!this_thread_interrupt_flag.is_set()) {
if (ft.wait_for(std::chrono::milliseconds(1)) ==
std::future_status::ready) {
break;
}
}
interruption_point();
}
从被中断的线程角度来看,中断就是一个 thread_interrupted 异常。因此检查出中断后,可以像异常一样对其进行处理
// sample
internal_thread = std::thread{[f, &p] {
p.set_value(&this_thread_interrupt_flag);
try {
f();
} catch (const thread_interrupted&) {
// 异常传入 std::thread 的析构函数时将调用 std::terminate
// 为了防止程序终止就要捕获异常
}
}};
假如有一个桌面搜索程序,除了与用户交互,程序还需要监控文件系统的状态,以识别任何更改并更新其索引。
为了避免影响 GUI 的响应性,这个处理通常会交给一个后台线程,后台线程需要运行于程序的整个生命周期。
这样的程序通常只在机器关闭时退出,而在其他情况下关闭程序,就需要井然有序地关闭后台线程,一个关闭方式就是中断
// sample
std::mutex config_mutex;
std::vector<InterruptibleThread> background_threads;
void background_thread(int disk_id) {
while (true) {
interruption_point();
fs_change fsc = get_fs_changes(disk_id);
if (fsc.has_changes()) {
update_index(fsc);
}
}
}
void start_background_processing() {
background_threads.emplace_back(background_thread, disk_1);
background_threads.emplace_back(background_thread, disk_2);
}
int main() {
start_background_processing();
process_gui_until_exit();
std::unique_lock<std::mutex> l(config_mutex);
for (auto& x : background_threads) {
x.interrupt();
}
// 中断所有线程后再join
for (auto& x : background_threads) {
if (x.joinable()) {
x.join();
}
}
// 不直接在一个循环里中断并 join 的目的是为了并发,
// 因为中断不会立即完成,它们必须进入下一个中断点,
// 再在退出前必要地调用析构和异常处理的代码,
// 如果对每个线程都中断后立即 join,就会造成中断线程的等待,
// 即使它还可以做一些有用的工作,比如中断其他线程
}