第八章 并发代码设计
第八章 并发代码设计
线程间的工作划分
为了提高线程利用率并最小化开销,必须决定要使用的线程数量,并为每个线程合理分配任务
开始处理之前的线程间数据划分
简单算法最容易并行化,比如要并行化 std::for_each,把元素划分到不同的线程上执行即可。
如何划分才能获取最优性能,取决于数据结构的细节,这里用一个最简单的划分为例,每 N 个元素分配给一个线程,每个线程不需要与其他线程通信,直到独立完成各自的处理任务(如下)。
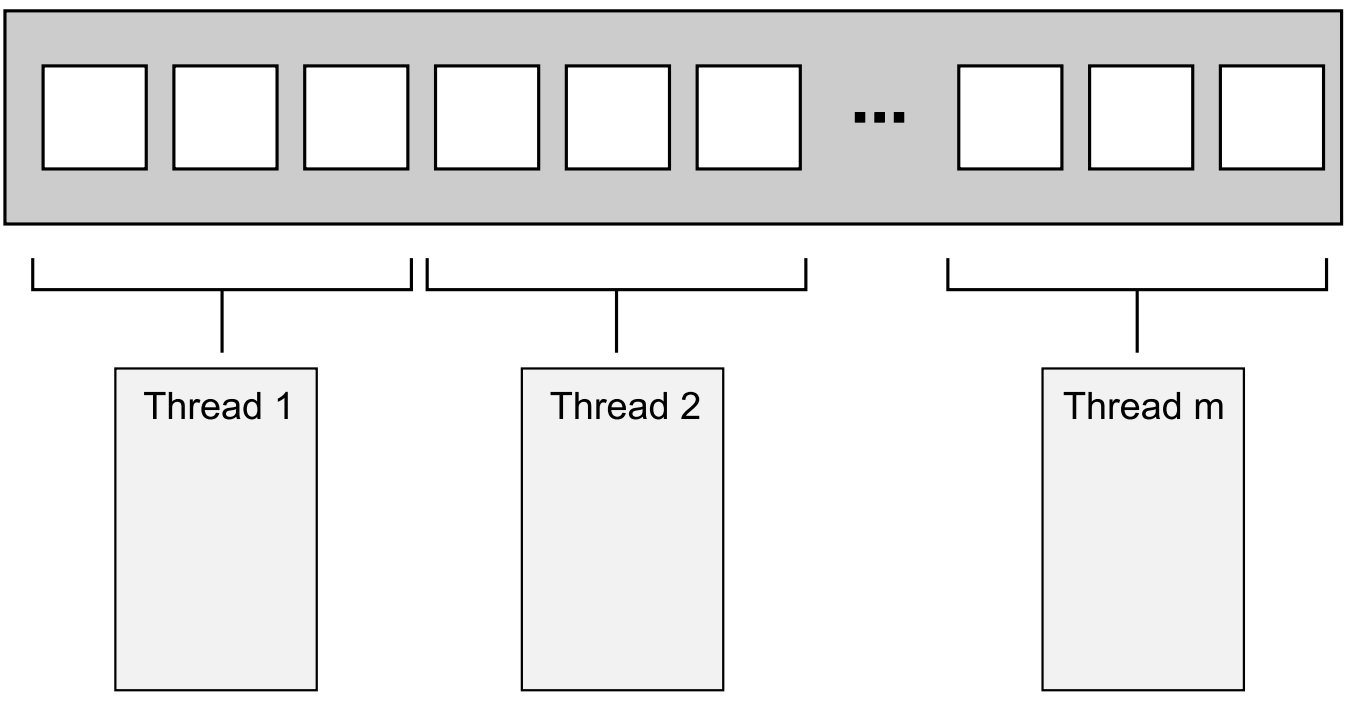
- 如果使用过 MPI 或 OpenMP,会很熟悉这个结构,即把一个任务划分成一系列并行任务,工作线程独立完成任务,最后 reduce 合并结果。
不过对 for_each 来说,最后的 reduce 实际不需要执行操作,但对其他需要合并结果的并行算法来说,最后一步很重要 - 尽管这个技术很强大,但不是万能的,有时数据不能灵活划分,只有在处理数据时划分才明显,最能明显体现这点的就是递归算法,比如快速排序
递归划分数据
要并行化快速排序,无法直接划分数据,因为只有处理之后才知道某一项应该置于基数的哪一边。
因此,很容易想到的是使用递归,其中的递归调用完全独立,各自处理不同的元素集,十分适合并发执行。
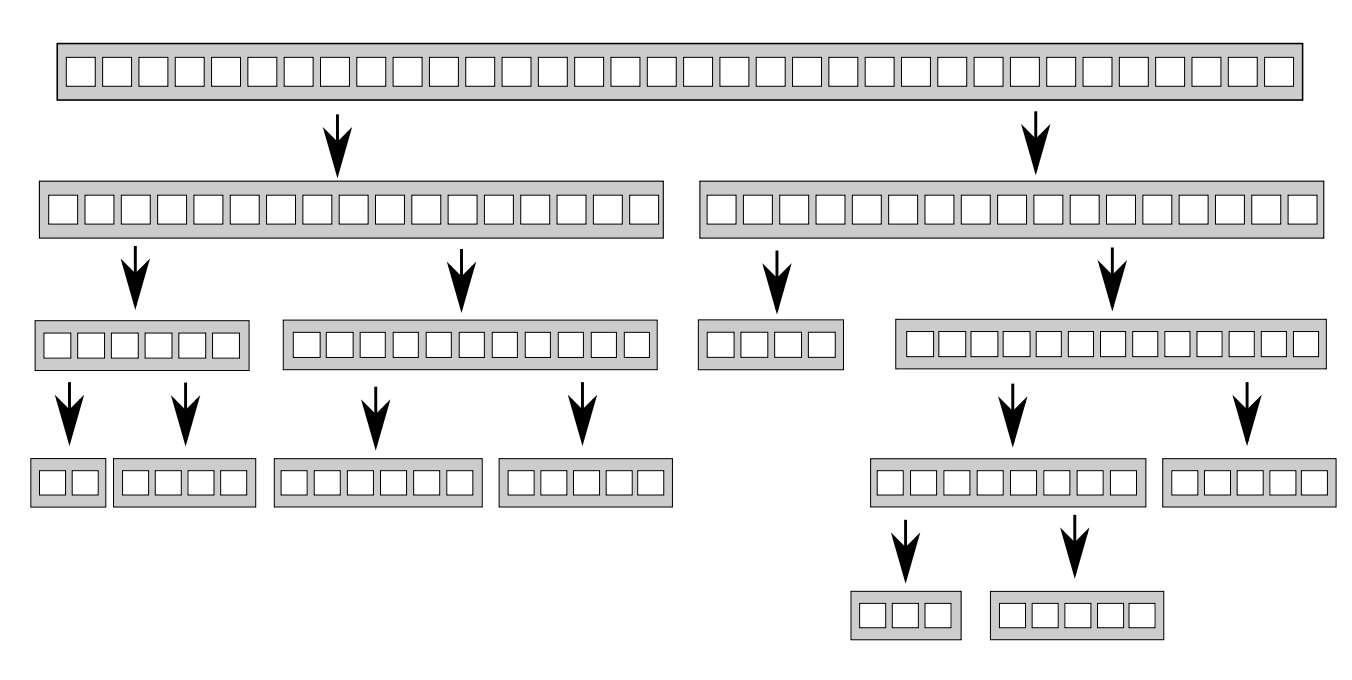
- 如果数据集很大,为每个递归生成新线程就会生成大量线程,如果线程过多就会影响性能。因此需要严格控制线程数,不过这个问题可以直接抛给 std::async
// parallel_quick_sort
template <typename T>
std::list<T> parallel_quick_sort(std::list<T> v) {
if (v.empty()) {
return {};
}
std::list<T> res;
res.splice(res.begin(), v, v.begin());
auto it = std::partition(v.begin(), v.end(),
[&](const T& x) { return x < res.front(); });
std::list<T> low;
low.splice(low.end(), v, v.begin(), it);
std::future<std::list<T>> l(
std::async(¶llel_quick_sort<T>, std::move(low)));
auto r(parallel_quick_sort(std::move(v)));
res.splice(res.end(), r);
res.splice(res.begin(), l.get());
return res;
}
Info
这段代码实现了并行快速排序(parallel quick sort), 输入链表非空的常规处理如下:
- 创建一个结果链表 res 来返回排序后的链表
- 使用list的 splice 函数将输入链表 v 的第一个元素转移到 res 中。
- 使用 std::partition 函数根据条件将 输入链表 v 分成两部分, 返回指向第二组元素中首元素的迭代器。
- 使用list的 splice 函数将重排序后的链表 v 中小于 res 的元素放在 low 中,其余的留在 v 中。
- 使用 std::async 异步地对 low 进行并行排序,并将结果存储在 l 中。
- 同时,它递归地对剩余的 v 进行排序,将结果存储在 r 中。
- 最后,将l和r的排序结果分别到res的头部和尾部并返回。
可以通过 hardware_concurrency 得知硬件可支持的线程数,再自己管理线程数。下面是一个使用 stack 存储已排序数据的并行快速排序:
// Parallel Quicksort using a stack of pending chunks to sort
template<typename T>
struct sorter
{
struct chunk_to_sort
{
std::list<T> data;
std::promise<std::list<T> > promise;
};
thread_safe_stack<chunk_to_sort> chunks;
std::vector<std::thread> threads;
unsigned const max_thread_count;
std::atomic<bool> end_of_data;
sorter() :
max_thread_count(std::thread::hardware_concurrency() - 1),
end_of_data(false)
{}
~sorter()
{
end_of_data = true;
for (unsigned i = 0; i < threads.size(); ++i)
{
threads[i].join();
}
}
void try_sort_chunk()
{
boost::shared_ptr<chunk_to_sort > chunk = chunks.pop();
if (chunk)
{
sort_chunk(chunk);
}
}
std::list<T> do_sort(std::list<T>& chunk_data)
{
if (chunk_data.empty())
{
return chunk_data;
}
std::list<T> result;
result.splice(result.begin(), chunk_data, chunk_data.begin());
T const& partition_val = *result.begin();
typename std::list<T>::iterator divide_point =
std::partition(chunk_data.begin(), chunk_data.end(),
[&](T const& val) {return val < partition_val; });
chunk_to_sort new_lower_chunk;
new_lower_chunk.data.splice(new_lower_chunk.data.end(), chunk_data,
chunk_data.begin(), divide_point);
std::future<std::list<T> > new_lower = new_lower_chunk.promise.get_future();
chunks.push(std::move(new_lower_chunk));
if (threads.size() < max_thread_count)
{
threads.push_back(std::thread(&sorter<T>::sort_thread, this));
}
std::list<T> new_higher(do_sort(chunk_data));
result.splice(result.end(), new_higher);
while (new_lower.wait_for(std::chrono::seconds(0)) !=
std::future_status::ready)
{
try_sort_chunk();
}
result.splice(result.begin(), new_lower.get());
return result;
}
void sort_chunk(boost::shared_ptr<chunk_to_sort > const& chunk)
{
chunk->promise.set_value(do_sort(chunk->data));
}
void sort_thread()
{
while (!end_of_data)
{
try_sort_chunk();
std::this_thread::yield();
}
}
};
template<typename T>
std::list<T> parallel_quick_sort(std::list<T> input)
{
if (input.empty())
{
return input;
}
sorter<T> s;
return s.do_sort(input);
}
基于任务类型划分(Dividing work by task type)
SoC: separation of concerns
在并发编程中,"关注点分离(SoC)"是一种设计原则,它的目标是将复杂系统的不同关注点分离成更小、更易于管理的部分。
一种基于任务的划分就使用了这个原则:
- 让线程针对性处理任务,对同一数据进行不同的操作,而不是都做相同的工作。
- 这样线程是独立的,每个线程只需要负责完成总任务的某一部分。
多线程不是一定要 SoC,比如线程间有很多共享数据,或者需要互相等待。
对于这样存在过多通信的线程,应该先找出通信的原因,如果所有的通信都关联同一个问题,合并成一个单线程来处理可能更好一些。
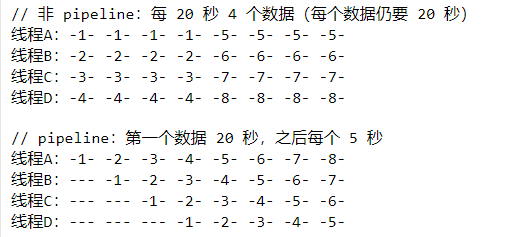
Pipeline
管道(pipeline)是一种并发执行策略,它允许你在系统中同时处理多个独立的数据项。
它的名称源于工作方式类似的物理管道:数据从一端输入,经过一系列操作(即管道中的各个阶段)后从另一端输出。
- Pipeline通过将任务划分为不同的阶段,每个阶段由一个核心处理,可以实现更平稳、更规律的数据处理。
然而,在初始阶段,由于需要等待所有核心都完成第一个数据项的处理,可能会导致整体处理时间延长。 - Pipeline的应用范围广泛,主要用于那些需要对大量独立数据项执行相同操作序列的任务。
例如,数据处理(如图像处理和视频解码)、软件编译(如词法分析、语法分析和代码生成)等。
样例参考:
影响并发代码性能的因素
- 处理器的数量和结构是影响多线程应用程序性能的关键因素。
- 如果你的应用程序的线程数少于处理器的核心数,你可能会浪费处理器的能力。
- 相反,如果你有超过处理器核心数的线程实际准备运行,你的应用程序将浪费处理器时间在线程之间切换,这种情况被称为超额订阅(oversubscription)。
- 随着处理器数量的增加,多个处理器试图访问同一数据的问题的可能性和性能影响也在增加。这可能会导致数据不一致和性能下降,需要通过适当的同步机制来解决。
- 使用 hardware_concurrency 可以获取硬件支持的线程数,但它不会考虑已运行在系统上的其他线程。可以考虑使用 std::async,它会适度处理并安排所有调用。另外也能用线程池解决。
- 需要注意的是并行运算可以显著提升性能,但并不是所有的任务都适合并行化。
- 有些任务由于其内在的序列性,可能无法有效地并行化。
- 线程之间的通信和同步也可能引入额外的开销,这可能会抵消并行计算带来的性能提升。
- 在设计并发程序时,我们需要仔细考虑这些因素,以确保我们能够有效地利用多线程的优势。
数据争用和乒乓缓存
在并发编程中,**数据争用(Data contention)**是一个重要的问题,尤其在多处理器环境下。
当多个线程在不同的处理器上试图同时访问和修改同一份数据时,就发生了数据争用。
**高争用(high contention)**是指多个处理器或线程在相同或相近的时间段内竞相访问同一资源。
在这种情况下,数据需要在不同的处理器之间频繁地传递,以保证每个处理器都能获取到数据的最新状态。
然而,这种频繁的数据传递往往会导致“乒乓缓存”现象的发生。
**乒乓缓存(Cache Ping-Pong)**是在多核处理器系统中经常出现的问题。它主要发生在多个CPU核心需要频繁地读写同一缓存行的数据时。
当一个处理器修改了某个数据,这个数据所在的缓存行就会被标记为“脏”。随后,这个“脏”缓存行需要在所有拥有该缓存行的处理器之间进行同步,以确保数据的一致性。
这个同步过程会消耗大量的时间,特别是在高争用的情况下,这种同步操作会变得非常频繁,从而导致处理器在等待数据传输时无法执行其他任务,最终影响应用程序的整体性能。
// Sample for Cache Ping-pong
// 1
std::atomic<unsigned long> counter(0);
void processing_loop()
{
while(counter.fetch_add(1,std::memory_order_relaxed)<100000000)
{
do_something();
}
}
// 2
std::mutex m;
my_data data;
void processing_loop_with_mutex()
{
while(true)
{
std::lock_guard<std::mutex> lk(m);
if(done_processing(data)) break;
}
}
- 针对样例1:
如果多个线程在不同处理器上运行此代码,counter的数据就需要在多个处理器之间来回传递,以确保每次 counter增加时,处理器上的 cache 都有最新的值。
这里就产生了乒乓缓存现象**。** - 针对样例2:
在多个处理器间传递的是互斥体 m. 如果处理器由于等待 m 转移而挂起,就只能干等着而不能做任何工作。
缓存行(Cache Line)****:
处理器缓存不直接处理单个内存位置,而是处理称为缓存行的内存块。
这些内存块通常为32或64字节大小,具体取决于使用的特定处理器模型。
因此,相邻内存位置的小数据项将在同一缓存行中。
伪共享(False Sharing):
伪共享是多线程编程中的一种性能降低现象,当多个线程访问同一缓存行中的不同数据时,即使这些数据在逻辑上是独立的,
由于它们在物理上位于同一缓存行中,也会导致缓存行在多个线程之间频繁地无效和更新,这就是伪共享。
::
超额订阅和任务切换
在多线程系统中,通常有比处理器更多的线程。
然而,如果有太多额外的线程,操作系统将不得不开始大量地进行任务切换,以确保它们都得到公平的时间片。
这可能会增加任务切换的开销,同时还会加剧由于接近性不足而导致的任何缓存问题。
- 数据的内存布局:
- 如果单个线程访问的数据在内存中分散开来,那么它可能位于不同的缓存行上。
- 反之,如果单个线程访问的数据在内存中靠近,那么它更可能位于同一缓存行上。
- 因此,如果数据分散,就必须从内存加载更多的缓存行到处理器缓存,这可能会增加内存访问延迟并降低性能。
- 任务切换的影响:
- 如果系统中的线程数多于核心数,每个核心将运行多个线程。
- 这增加了对缓存的压力,因为你试图确保不同的线程访问不同的缓存行,以避免假共享。
- 因此,当处理器切换线程时,如果每个线程使用的数据分布在多个缓存行上,那么它更可能需要重新加载缓存行。
- 操作系统的调度策略:
- 如果线程数多于核心或处理器,操作系统可能会选择在一个时间片上在一个核心上调度一个线程,然后在下一个时间片上在另一个核心上调度。
- 这将需要将该线程的数据的缓存行从第一个核心的缓存转移到第二个核心的缓存;需要转移的缓存行越多,这将越耗时。
为多线程性能设计数据结构
在为多线程性能设计数据结构时,关键考虑因素包括争用、伪共享和数据接近性。这三个因素都可能对性能产生重大影响,而通常只需通过改变数据布局或更改哪些数据元素分配给哪个线程就可以改善情况。
- 数据布局可以影响性能,即使数据不与任何其他线程共享。
- 在数组和其他数据结构中的数据访问模式显著影响性能。访问连续元素比从各处访问值要好,因为这减少了缓存使用和伪共享的机会。
- 将结果矩阵划分为小的正方形或近似正方形的块,而不是让每个线程处理一小部分行的全部,可能会更好。
比如下面的结果矩阵是C, 假设把它分成4*4的正方形小矩阵,每个负责计算小结果矩阵的线程只用访问A, B两个矩阵的部分数据,避免了大量的伪共享问题。
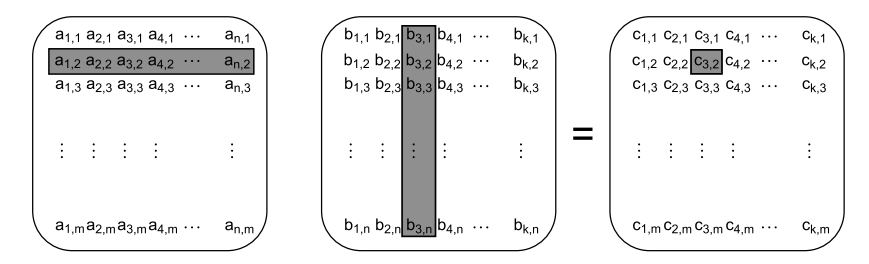
- 同样的原则适用于任何你需要在线程之间划分大块数据的情况;仔细查看所有的数据访问模式的方面,并确定性能损失的可能原因。
在设计并发时,除了数据访问模式,还有其他要考虑的因素,例如,二叉树本质上很难在子树以外的任何单元中进行划分,这可能有用也可能无用,这取决于树的平衡程度以及你需要将其划分成多少部分。
- 伪共享也可能是受互斥锁保护的数据的问题。
如果互斥锁和数据项在内存中靠得很近,这对于获取互斥锁的线程来说是理想的;但也有一个缺点:如果其他线程试图在第一个线程持有互斥锁时锁定互斥锁,它们将需要访问那个内存。
这可能会导致拥有互斥锁的线程在缓存中持有的数据被无效。- 当一个线程尝试获取一个已经被其他线程持有的互斥锁时,它会执行一个读-修改-写操作。
- 即使这个操作没有成功(因为锁已经被持有),它仍然可能导致缓存系统将该缓存行标记为无效,因为它可能已经被修改(尽管实际上没有)。
- 如果互斥锁和数据项在同一个缓存行中,那么即使数据项本身并没有被修改,缓存行的失效也可能导致持有锁的线程需要从主内存中重新加载数据,这会增加延迟并可能降低性能。
- 这种设计是为了保证数据的一致性,避免出现一个处理器正在读取一个数据项,而另一个处理器同时修改这个数据项的情况。
- 避免伪共享的策略
数据对齐和填充:在数据结构中添加填充,以确保互斥锁和它保护的数据不在同一个缓存行中。
例如,你可以在互斥锁和数据项之间添加一些填充,使它们不会出现在同一个缓存行中。这样,一个线程对互斥锁的操作就不太可能影响到其他线程缓存中的数据。:::success
// 用如下方式测试 mutex 竞争问题
struct protected_data { std::mutex m; char padding[64]; // 填充,大小取决于你的硬件的缓存行大小 my_data data_to_protect; };// 用如下方式测试数组数据伪共享,如果性能提高了就说明伪共享影响了性能,并且可以保留填充或者用其他方式重排数据访问来消除伪共享
struct Data { data_item1 d1; data_item2 d2; char padding[std::hardware_destructive_interference_size]; }; Data some_array[256];
:::
避免不必要的共享:如果可能,尽量减少线程之间的数据共享。例如,如果每个线程都有自己的独立数据,那么就可以完全避免伪共享。
线程和数据的亲和性:尽量让相同的线程处理相同的数据。这样,数据就可能始终保持在该线程的缓存中,从而避免缓存失效。
使用无锁数据结构:无锁数据结构是一种特殊类型的数据结构,它们被设计为在没有锁的情况下支持并发访问。这些数据结构通常使用原子操作来同步线程,从而避免了锁的开销和伪共享问题。
优化数据访问模式:尽量让线程访问连续的内存区域,这样可以利用缓存的空间局部性,减少缓存未命中的可能性。
设计并发时的额外考虑因素
设计并发代码还需要考虑诸如异常安全性和可扩展性等事项:
- 需要确保即使发生异常,也能保持系统的完整性和稳定性。
- 需要考虑如何使代码能够充分利用多核处理器资源,以实现良好的可扩展性。
Exception safety in parallel algorithms
并行算法比串行算法更注重异常问题。
- 如果串行算法中的一个操作抛出一个异常,算法只需要确保避免资源泄漏和破坏不变性;可以让异常传播给调用者处理。
- 但在并行算法中,许多操作运行在不同的线程上,异常就不允许传播,因为它在错误的调用栈上。
如果在新线程上的函数以异常退出,应用程序将被终止。
回顾以前提到的并行版本的 std::accumulate,它就是非异常安全的,代码可能抛出异常的位置如下
// a parallel version of std::accumulate
#include <algorithm>
#include <functional>
#include <numeric>
#include <thread>
#include <vector>
template <typename Iterator, typename T>
struct accumulate_block {
void operator()(Iterator first, Iterator last, T& res) {
res = std::accumulate(first, last, res); // 可能抛异常
}
};
template <typename Iterator, typename T>
T parallel_accumulate(Iterator first, Iterator last, T init) {
std::size_t len = std::distance(first, last); // 此时没做任何事,抛异常无影响
if (!len) {
return init;
}
std::size_t min_per_thread = 25;
std::size_t max_threads = (len + min_per_thread - 1) / min_per_thread;
std::size_t hardware_threads = std::thread::hardware_concurrency();
std::size_t num_threads =
std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads);
std::size_t block_size = len / num_threads;
std::vector<T> res(num_threads); // 仍未做任何事,抛异常无影响
std::vector<std::thread> threads(num_threads - 1); // 同上
Iterator block_start = first; // 同上
for (std::size_t i = 0; i < num_threads - 1; ++i) {
Iterator block_end = block_start; // 同上
std::advance(block_end, block_size);
// 下面创建 std::thread,抛异常就导致析构对象,并调用 std::terminate
// 终止程序
threads[i] = std::thread(accumulate_block<Iterator, T>{}, block_start,
block_end, std::ref(res[i]));
block_start = block_end;
}
// accumulate_block::operator() 调用的 std::accumulate
// 可能抛异常,此时抛异常造成问题同上
accumulate_block<Iterator, T>()(block_start, last, res[num_threads - 1]);
std::for_each(threads.begin(), threads.end(),
std::mem_fn(&std::thread::join));
// 最后调用 std::accumulate 可能抛异常,但不引发大问题,因为所有线程已 join
return std::accumulate(res.begin(), res.end(), init);
}
- 上面已经分析了所有可能抛出异常的位置,下面来处理这些问题。新线程想做的是返回计算结果,但可能抛出异常导致 std::thread 析构,而析构没被 join 的 std::thread 将导致程序终止。解决这个问题很简单,结合使用 std::packaged_task 和 std::future,再把工作线程的异常抛出到主线程,让主线程处理即可
// using std::packaged_task
#include <algorithm>
#include <functional>
#include <future>
#include <numeric>
#include <thread>
#include <vector>
template <typename Iterator, typename T>
struct accumulate_block {
T operator()(Iterator first, Iterator last) {
return std::accumulate(first, last, T{});
}
};
template <typename Iterator, typename T>
T parallel_accumulate(Iterator first, Iterator last, T init) {
std::size_t len = std::distance(first, last);
if (!len) {
return init;
}
std::size_t min_per_thread = 25;
std::size_t max_threads = (len + min_per_thread - 1) / min_per_thread;
std::size_t hardware_threads = std::thread::hardware_concurrency();
std::size_t num_threads =
std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads);
std::size_t block_size = len / num_threads;
std::vector<std::future<T>> fts(num_threads - 1); // 改用 std::future 获取值
std::vector<std::thread> threads(num_threads - 1);
Iterator block_start = first;
for (std::size_t i = 0; i < num_threads - 1; ++i) {
Iterator block_end = block_start;
std::advance(block_end, block_size);
// 用 std::packaged_task 替代直接创建 std::thread
std::packaged_task<T(Iterator, Iterator)> pt(
accumulate_block<Iterator, T>{});
fts[i] = pt.get_future();
threads[i] = std::thread(std::move(pt), block_start, block_end);
block_start = block_end;
}
T last_res = accumulate_block<Iterator, T>{}(block_start, last);
std::for_each(threads.begin(), threads.end(),
std::mem_fn(&std::thread::join));
T res = init;
try {
for (std::size_t i = 0; i < num_threads - 1; ++i) {
res += fts[i].get();
}
res += last_res;
} catch (...) {
for (auto& x : threads) {
if (x.joinable()) {
x.join();
}
}
throw;
}
return res;
}
- 不过 try-catch 很难看,并且导致了重复代码(正常控制流和 catch 块都对线程执行 join),因此可以用 RAII 来处理
// An exception-safe parallel version of std::accumulate
#include <algorithm>
#include <functional>
#include <future>
#include <numeric>
#include <thread>
#include <vector>
class threads_guard {
public:
explicit threads_guard(std::vector<std::thread>& threads)
: threads_(threads) {}
~threads_guard() {
for (auto& x : threads_) {
if (x.joinable()) {
x.join();
}
}
}
private:
std::vector<std::thread>& threads_;
};
template <typename Iterator, typename T>
struct accumulate_block {
T operator()(Iterator first, Iterator last) {
return std::accumulate(first, last, T{});
}
};
template <typename Iterator, typename T>
T parallel_accumulate(Iterator first, Iterator last, T init) {
std::size_t len = std::distance(first, last);
if (!len) {
return init;
}
std::size_t min_per_thread = 25;
std::size_t max_threads = (len + min_per_thread - 1) / min_per_thread;
std::size_t hardware_threads = std::thread::hardware_concurrency();
std::size_t num_threads =
std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads);
std::size_t block_size = len / num_threads;
std::vector<std::future<T>> fts(num_threads - 1);
std::vector<std::thread> threads(num_threads - 1);
threads_guard g{threads}; // threads 元素析构时自动 join
Iterator block_start = first;
for (std::size_t i = 0; i < num_threads - 1; ++i) {
Iterator block_end = block_start;
std::advance(block_end, block_size);
std::packaged_task<T(Iterator, Iterator)> pt(
accumulate_block<Iterator, T>{});
fts[i] = pt.get_future();
threads[i] = std::thread(std::move(pt), block_start, block_end);
block_start = block_end;
}
T last_res = accumulate_block<Iterator, T>{}(block_start, last);
std::for_each(threads.begin(), threads.end(),
std::mem_fn(&std::thread::join));
T res = init;
for (std::size_t i = 0; i < num_threads - 1; ++i) {
res += fts[i].get();
}
res += last_res;
return res;
}
- 更优雅的方式是使用 std::async
// using std::async
#include <future>
#include <numeric>
template <typename Iterator, typename T>
T parallel_accumulate(Iterator first, Iterator last, T init) {
std::size_t len = std::distance(first, last);
std::size_t max_chunk_size = 25;
if (len <= max_chunk_size) {
return std::accumulate(first, last, init);
}
Iterator mid_point = first;
std::advance(mid_point, len / 2);
std::future<T> l =
std::async(parallel_accumulate<Iterator, T>, first, mid_point, init);
// 递归调用如果抛出异常,std::async 创建的 std::future 将在异常传播时被析构
T r = parallel_accumulate(mid_point, last, T{});
// 如果异步任务抛出异常,get 就会捕获异常并重新抛出
return l.get() + r;
}
Scalability and Amdahl’s law
可扩展性(Scalability)
在并发编程中,可扩展性是指应用程序能够利用系统中的额外处理器的能力。
如果一个应用程序具有良好的可扩展性,那么当你向系统添加更多的处理器时,应用程序的性能应该会提高。
换句话说,可扩展性是关于减少执行一个动作所需的时间或增加在添加更多处理器时可以在给定时间内处理的数据量。
阿姆达尔定律(Amdahl’s Law)
阿姆达尔定律是一个用于估计通过增加处理器数量来实现的潜在性能提升的公式。
阿姆达尔定律的基本思想是,一个程序的执行时间由其可并行化的部分和不可并行化的部分(即串行部分)决定。
阿姆达尔定律的公式如下:

其中,P 是性能提升,fs 是程序中串行部分的比例,N 是处理器的数量。
这个公式告诉我们,无论我们有多少处理器,串行部分总是会限制我们的性能提升。因此,为了提高并发程序的性能,我们需要尽可能地减少串行部分,增加并行部分。
Hiding latency with multiple threads
使用多线程隐藏延迟主要是理解并管理线程的阻塞状态。通过合理的线程调度和可能的优化策略,可以有效地利用CPU资源,提高系统的整体效率。
- 在多线程程序中,线程并不总是处于“全速”运行状态。然而,实际上线程经常在等待某件事情时阻塞。
例如等待I/O操作完成、获取锁、等待其他线程的通知或只是简单的休眠。 - 如果只有和处理器单元一样多的线程,阻塞就意味着浪费 CPU 时间。
当知道某个线程可能会长时间等待时,可以运行额外的线程来利用这个“空闲”的CPU时间。- _样例:_在病毒扫描应用中,一个线程搜索文件并放入队列,另一个线程从队列中取出文件并扫描。由于搜索线程受I/O限制,可以添加额外的扫描线程来利用空闲的CPU时间。
- 线程的数量并不是越多越好。过多的线程会导致系统花费更多时间在任务切换上,从而降低性能。最优的线程数量将高度依赖于正在完成的工作的性质和线程花费在等待上的时间的百分比。
- 利用空闲的 CPU 时间也可能不需要运行额外的线程。例如,如果一个线程因为等待 I/O 操作而阻塞,使用异步 I/O 就是合理的,当 I/O 操作异步运行在后台时,线程就能做其他有用的工作。
- 有时候添加线程以确保及时处理外部事件是值得的方式,以提高系统的响应能力。
Improving responsiveness with concurrency
应用程序需要响应不同的用户输入操作,为了确保用户输入能得到及时处理,必须以合理的频率调用事件获取和处理函数。
我们可以将长时间运行的任务放在一个全新的线程上,并留一个专用的用户线程来处理事件。这样,即使任务需要很长时间,用户线程也总是能够及时响应事件。这种响应性通常是使用应用程序时用户体验的关键。
当执行特定操作(无论是什么)时完全锁定的应用程序使用起来很不方便。通过提供一个专用的事件处理线程,GUI可以处理GUI特定的消息,而不中断耗时的处理的执行,同时仍然传递那些确实影响长时间运行任务的相关消息。
这样,我们就可以在保证应用程序响应性的同时,有效地执行长时间运行的任务。这是通过并发来分离关注点,以解决应用程序中的响应问题的一种有效方法。
// Sample
std::thread task_thread;
std::atomic<bool> task_cancelled(false);
void gui_thread() {
while (true) {
event_data event = get_event();
if (event.type == quit) {
break;
}
process(event);
}
}
void task() {
while (!task_complete() && !task_cancelled) do_next_operation();
if (task_cancelled) {
perform_cleanup();
} else {
post_gui_event(task_complete);
}
}
void process(const event_data& event) {
switch (event.type) {
case start_task:
task_cancelled = false;
task_thread = std::thread(task);
break;
case stop_task:
task_cancelled = true;
task_thread.join();
break;
case task_complete:
task_thread.join();
display_results();
break;
default:
...
}
}
并发代码设计实践
下面为标准库的三个算法实现并行版本,这些实现仅是为了阐述技术的运用,而不是最先进高效的实现。更先进的实现可以在学术文献或专业的多线程库(如 Intel 的 Threading Building Blocks) 中找到。
并行版 std::for_each
stdfor_each 与之前介绍的并行版 stdpackaged_task 和 std::future 在线程间传递异常。
// A parallel version of std::for_each
#include <algorithm>
#include <future>
#include <thread>
#include <vector>
template <typename Iterator, typename Func>
void parallel_for_each(Iterator first, Iterator last, Func f) {
std::size_t len = std::distance(first, last);
if (!len) {
return;
}
std::size_t min_per_thread = 25;
std::size_t max_threads = (len + min_per_thread - 1) / min_per_thread;
std::size_t hardware_threads = std::thread::hardware_concurrency();
std::size_t num_threads =
std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads);
std::size_t block_size = len / num_threads;
std::vector<std::future<void>> fts(num_threads - 1);
std::vector<std::jthread> threads(num_threads - 1);
Iterator block_start = first;
for (std::size_t i = 0; i < num_threads - 1; ++i) {
Iterator block_end = block_start;
std::advance(block_end, block_size);
std::packaged_task<void(void)> pt(
[=] { std::for_each(block_start, block_end, f); });
fts[i] = pt.get_future();
threads[i] = std::jthread(std::move(pt));
block_start = block_end;
}
std::for_each(block_start, last, f);
for (std::size_t i = 0; i < num_threads - 1; ++i) {
fts[i].get(); // 只是为了传递异常
}
}
使用 std::async 进行简化:
// A parallel version of stdasync
#include <algorithm>
#include <future>
template <typename Iterator, typename Func>
void parallel_for_each(Iterator first, Iterator last, Func f) {
std::size_t len = std::distance(first, last);
if (!len) {
return;
}
std::size_t min_per_thread = 25;
if (len < 2 * min_per_thread) {
std::for_each(first, last, f);
return;
}
const Iterator mid_point = first + len / 2;
std::future<void> l =
std::async(¶llel_for_each<Iterator, Func>, first, mid_point, f);
parallel_for_each(mid_point, last, f);
l.get();
}
并行版 std::find
- std::find 的不同之处在于,只要找到目标值就应该停止继续查找。在并行版本中,一个线程找到了值,不仅自身要停止继续查找,还应该通知其他线程停止,这点可以使用一个原子变量作为标记来实现。
- 有两种可选方式来返回值和传播异常,一是使用 stdpackaged_task 将返回值和异常交给主线程处理,二是使用 stdpromise,如果想让其他线程继续搜索则使用 stdfind 的 std::promise。
// An implementation of a parallel find algorithm
#include <algorithm>
#include <atomic>
#include <functional>
#include <future>
#include <numeric>
#include <thread>
#include <vector>
template <typename Iterator, typename T>
Iterator parallel_find(Iterator first, Iterator last, T match) {
struct find_element {
void operator()(Iterator begin, Iterator end, T match,
std::promise<Iterator>* res, std::atomic<bool>* done_flag) {
try {
for (; begin != end && !done_flag->load(); ++begin) {
if (*begin == match) {
res->set_value(begin);
done_flag->store(true);
return;
}
}
} catch (...) {
try {
res->set_exception(std::current_exception());
done_flag->store(true);
} catch (...) {
}
}
}
};
std::size_t len = std::distance(first, last);
if (!len) {
return last;
}
std::size_t min_per_thread = 25;
std::size_t max_threads = (len + min_per_thread - 1) / min_per_thread;
std::size_t hardware_threads = std::thread::hardware_concurrency();
std::size_t num_threads =
std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads);
std::size_t block_size = len / num_threads;
std::promise<Iterator> res;
std::atomic<bool> done_flag(false);
{
std::vector<std::jthread> threads(num_threads - 1);
Iterator block_start = first;
for (auto& x : threads) {
Iterator block_end = block_start;
std::advance(block_end, block_size);
x = std::jthread(find_element{}, block_start, block_end, match, &res,
&done_flag);
block_start = block_end;
}
find_element{}(block_start, last, match, &res, &done_flag);
}
if (!done_flag.load()) {
return last;
}
return res.get_future().get();
}
使用 std::async 进行简化:
// An implementation of a parallel find algorithm using std::async
#include <iostream>
#include <vector>
#include <numeric> // std::partial_sum
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5};
std::partial_sum(numbers.begin(), numbers.end(), numbers.begin());
for (int num : numbers) {
std::cout << num << ' ';
}
return 0;
}
// 这段代码会输出:1 3 6 10 15,这就是原始序列中每个元素及其之前所有元素的累积和。
并行版 std::partial_sum
std::partial_sum 会遍历一个序列(通常是一个数组或者向量),并将每个元素替换为原始序列中该元素及其之前所有元素的和。参考使用样例为:
simple usage of std::partial_sum Expand source
实现并行版本时,第一种划分方式就是传统的按块划分
Info
1 1 1 1 1 1 1 1 1 // 输入 9 个 1
// 划分为三部分
1 1 1
1 1 1
1 1 1
// 得到三个部分的结果
1 2 3
1 2 3
1 2 3
// 将第一部分的尾元素(即 3)加到第二部分
1 2 3
4 5 6
1 2 3
// 再将第二部分的尾元素(即 6)加到第三部分
1 2 3
4 5 6
7 8 9
由于需要线程间同步,这个实现不容易简单地用 std::async 重写
Sample
#include <algorithm>
#include <future>
#include <numeric>
template <typename Iterator>
void parallel_partial_sum(Iterator first, Iterator last) {
using value_type = typename Iterator::value_type;
struct process_chunk {
void operator()(Iterator begin, Iterator last,
std::future<value_type>* previous_end_value,
std::promise<value_type>* end_value) {
try {
Iterator end = last;
++end;
std::partial_sum(begin, end, begin);
if (previous_end_value) { // 不是第一个块
value_type addend = previous_end_value->get();
*last += addend;
if (end_value) {
end_value->set_value(*last);
}
std::for_each(begin, last,
[addend](value_type& item) { item += addend; });
} else if (end_value) {
end_value->set_value(*last); // 是第一个块则可以为下个块更新尾元素
}
} catch (...) {
// 如果抛出异常则存储到
// std::promise,异常会传播给下一个块(获取这个块的尾元素时)
if (end_value) {
end_value->set_exception(std::current_exception());
} else {
throw; // 异常最终传给最后一个块,此时再抛出异常
}
}
}
};
std::size_t len = std::distance(first, last);
if (!len) {
return;
}
std::size_t min_per_thread = 25;
std::size_t max_threads = (len + min_per_thread - 1) / min_per_thread;
std::size_t hardware_threads = std::thread::hardware_concurrency();
std::size_t num_threads =
std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads);
std::size_t block_size = len / num_threads;
// end_values 存储块内尾元素值
std::vector<std::promise<value_type>> end_values(num_threads - 1);
// prev_end_values 检索前一个块的尾元素
std::vector<std::future<value_type>> prev_end_values;
prev_end_values.reserve(num_threads - 1);
Iterator block_start = first;
std::vector<std::jthread> threads(num_threads - 1);
for (std::size_t i = 0; i < num_threads - 1; ++i) {
Iterator block_last = block_start;
std::advance(block_last, block_size - 1); // 指向尾元素
threads[i] = std::jthread(process_chunk{}, block_start, block_last,
i != 0 ? &prev_end_values[i - 1] : nullptr,
&end_values[i]);
block_start = block_last;
++block_start;
prev_end_values.emplace_back(end_values[i].get_future());
}
Iterator final_element = block_start;
std::advance(final_element, std::distance(block_start, last) - 1);
process_chunk{}(block_start, final_element,
num_threads > 1 ? &prev_end_values.back() : nullptr, nullptr);
}
如果处理器核数非常多,就没必要使用上面的方式了,因为还有并发度更高的方式,即隔一定距离计算,每轮计算完成,下一轮计算使用的距离变为之前的两倍。
这种方式不再需要进一步同步,因为所有中间的结果都直接传给了下一个需要这些结果的处理器,但实际上很少有处理器可以在多条数据上同时执行同一条指令(即 SIMD),
因此必须为通用情况设计代码,在每步操作上显式同步线程,比如使用 barrier 的同步机制,直到所有线程到达 barrier 时才能继续执行下一步。
Info
1 1 1 1 1 1 1 1 1 // 输入 9 个 1
// 先让距离为 1 的元素相加
1 2 2 2 2 2 2 2 2
// 再让距离为 2 的元素相加
1 2 3 4 4 4 4 4 4
// 再让距离为 4 的元素相加
1 2 3 4 5 6 7 8 8
// 再让距离为 8 的元素相加
1 2 3 4 5 6 7 8 9