第七章 无锁并发数据结构
第七章 无锁并发数据结构
非阻塞数据结构
阻塞的算法和数据结构使用mutex, condition_variable,future来同步数据,但非阻塞并不等同于 lock-free。
比如第五章提到的自旋锁没有使用阻塞函数的调用,是非阻塞的,但并非是 lock-free.
- 阻塞线程:
- 线程因为等待某个事件而被暂时挂起,无法执行。
- 阻塞可能导致系统性能问题,因为线程需要等待资源或其他线程的操作完成。
- 饥饿线程:
- 线程无法获得所需资源,导致长时间等待。
- 当等待时间对进程的推进和响应产生明显影响时,称为进程饥饿。
非阻塞数据结构允许多个线程同时访问数据结构,而不会导致线程被阻塞。
对于非阻塞的数据结构由松到严可分为三个等级:
- obstruction-free(无障碍):
obstruction-freedom是最弱的非阻塞数据结构形式。
这里,我们只要求在所有其他线程都挂起的情况下能保证一个线程继续执行。更准确地说,如果除开某线程的所有其他线程都挂起,则此线程不会继续处于饥饿(starve)状态。
A method is obstruction-free if, from any point after which it executes in isolation,
it finishes in a finite number of steps (method call executes in isolation if no other threads take steps).
- lock-free(无锁):
- 如果数据提供了无锁性(lock-freedom), 任何时候至少有一个线程可以继续执行。
- 满足 lock-free 必定满足 obstruction-free
- 与无阻塞的区别在于: 即使没有线程被挂起,也至少有一个非饥饿线程。
- A method is lock-free if it guarantees that infinitely often some method call finishes in a finite number of steps.
- wait-free(无等待):
- 如果数据结构是lock-free且每个线程都保证在有限步骤内继续执行,那么它是无等待的数据结构。线程不会因为“unreasonably large”的步骤而饥饿。
- 满足 wait-free 必定满足 lock-free,但 wait-free 很难实现,因为要保证有限步数内完成操作,就要保证操作一次通过,并且执行到某一步不能导致其他线程操作失败。
- A method is wait-free if it guarantees that every call finishes its execution in a finite number of steps.
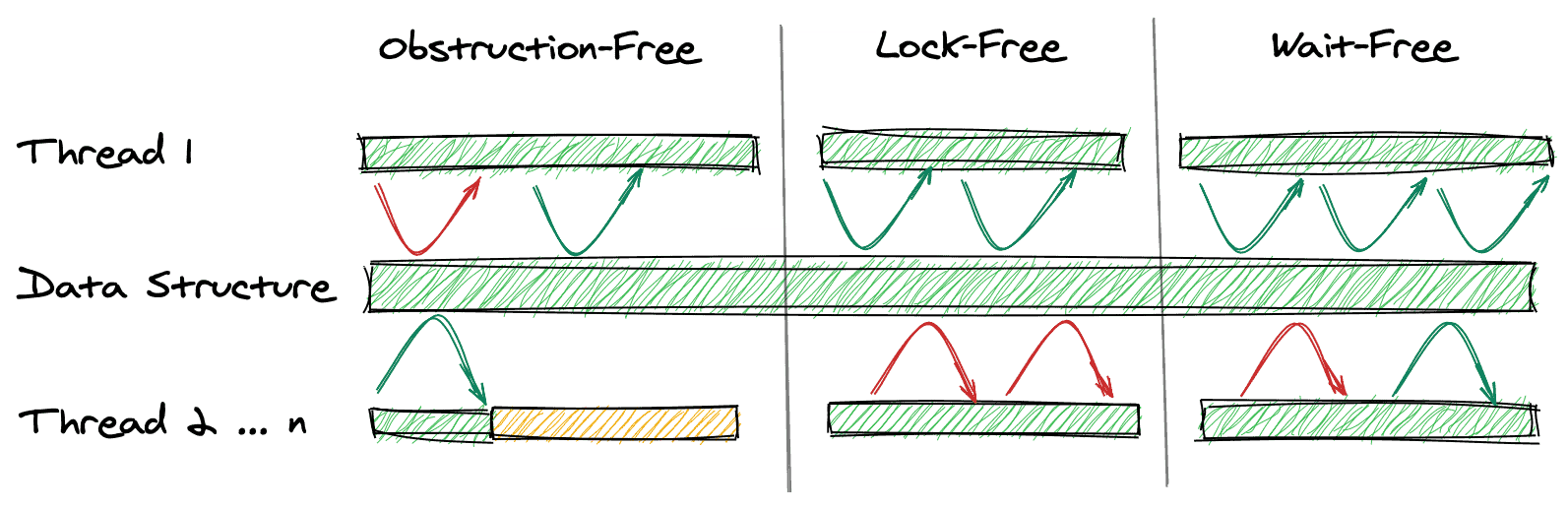
- 无障碍:当底部线程挂起(黄色), 顶部的线程1可以继续运行(绿色箭头)
- 无锁: 至少线程1可以继续运行,其他线程可能陷入困境(红色箭头)
- 无等待: 这里可以保证线程1在饥饿一段时间(红色箭头)可以继续运行(绿色箭头)
Info
lock-free
- lock-free 数据结构必须允许多线程并发访问,但它们不能做相同操作,比如一个 lock-free 的 queue 允许一个线程 push、另一个线程 pop,但不允许两个线程同时 push。
此外,如果一个访问 lock-free 数据结构的线程被中途挂起,其他线程必须能完成操作而不需要等待挂起的线程 - 使用 lock-free 数据结构主要是为了最大化并发访问,不需要阻塞。
第二个原因是鲁棒性,如果线程在持有锁时死掉就会导致数据结构被永久破坏,而对 lock-free 数据结构来说,除了死掉的线程里的数据,其他的数据都不会丢失。
lock-free 没有任何锁,所以一定不会出现死锁 - 但 lock-free 可能造成更大开销,用于 lock-free 的原子操作比非原子操作慢得多,且 lock-free 数据结构中的原子操作一般比 lock-based 中的多,此外,硬件必须访问同一个原子变量以在线程间同步数据。
无论 lock-free 还是 lock-based,性能方面的检查(最坏情况等待时间、平均等待时间、总体执行时间或其他方面)都是非常重要的
lock-free thread-safe stack
- 最简单的 stack 实现方式是包含头节点指针的链表。push 的过程很简单,创建一个新节点,然后让新节点的 next 指针指向当前 head,最后 head 设为新节点
- 这里的 race condition 在于,如果两个线程同时 push,让各自的新节点的 next 指针指向当前 head,这样必然导致 head 最终设为二者之一的新节点,而另一个被丢弃
- 解决方法是,在最后设置 head 时先进行判断,只有当前 head 与新节点的 next 相等,才将 head 设为新节点,如果不等则让 next 指向当前 head 并重新判断。
而这个操作必须是原子的,因此就需要使用 compare_exchange_weak,不需要使用 compare_exchange_strong,因为 compare_exchange_weak 在相等时可能替换失败,但替换失败也会返回 false,放在循环里带来的效果是一样的,
而 compare_exchange_weak 在一些机器架构上可以产生比 compare_exchange_strong 更优化的代码.
// Implementing push() without locks
#include <atomic>
template <typename T>
class LockFreeStack
{
public:
void push(const T& x)
{
Node* t = new Node(x);
t->next = head_.load();
while (!head_.compare_exchange_weak(t->next, t)) { }
}
private:
struct Node
{
T v;
Node* next = nullptr;
Node(const T& x) : v(x) {}
};
private:
std::atomic<Node*> head_;
};
pop 的过程很简单,先存储当前头节点指针,再将头节点设为下一节点,最后返回存储的头节点并删除指针。
这里的 race condition 在于,如果两个线程同时 pop,如果一个已经删除了头节点,另一个线程读取头节点的下一节点就访问了空悬指针. 先绕开删除指针这一步,考虑前几步的实现。
// pop
template <typename T>
void LockFreeStack<T>::pop(T& res) {
Node* t = head_.load(); // 未考虑头节点为空指针的情况
while (!head_.compare_exchange_weak(t, t->next)) {}
res = t->v;
}
- 传引用来保存结果的原因是,如果直接返回值,返回前一定会先移除元素,如果拷贝返回值时抛出异常,移除的元素就丢失了。
但传引用的问题是,如果其他线程移除了节点,被移除的节点不能被解引用,当前线程就无法安全地拷贝数据。因此,如果想安全地返回值,应该返回智能指针.
释放被移除的节点的难点在于,一个线程在释放内存时,无法得知其他线程是否持有要释放的指针.
只要没有其他线程调用 pop,就能安全释放,因此可以用一个计数器来记录调用 pop 的线程数,计数不为 1 时,先把节点添加到待删除节点列表中,计数为 1 则安全释放.
// support delete
#include <atomic>
#include <memory>
template <typename T>
class LockFreeStack {
public:
void push(const T& x) {
Node* t = new Node(x);
t->next = head_.load();
while (!head_.compare_exchange_weak(t->next, t)) {
}
}
std::shared_ptr<T> pop() {
++pop_cnt_;
Node* t = head_.load();
while (t && !head_.compare_exchange_weak(t, t->next)) {
}
std::shared_ptr<T> res;
if (t) {
res.swap(t->v);
}
try_delete(t);
return res;
}
private:
struct Node {
std::shared_ptr<T> v;
Node* next = nullptr;
Node(const T& x) : v(std::make_shared<T>(x)) {}
};
private:
static void delete_list(Node* head) {
while (head) {
Node* t = head->next;
delete head;
head = t;
}
}
void append_to_delete_list(Node* first, Node* last) {
last->next = to_delete_list_;
// 确保 last->next 为 to_delete_list_,再设置 first 为新的头节点
while (!to_delete_list_.compare_exchange_weak(last->next, first)) {
}
}
void append_to_delete_list(Node* head) {
Node* last = head;
while (Node* t = last->next) {
last = t;
}
append_to_delete_list(head, last);
}
void try_delete(Node* head) {
if (pop_cnt_ == 0) {
return;
}
if (pop_cnt_ > 1) {
append_to_delete_list(head, head);
--pop_cnt_;
return;
}
Node* t = to_delete_list_.exchange(nullptr);
if (--pop_cnt_ == 0) {
delete_list(t);
} else if (t) {
append_to_delete_list(t);
}
delete head;
}
private:
std::atomic<Node*> head_;
std::atomic<std::size_t> pop_cnt_;
std::atomic<Node*> to_delete_list_;
};
- 如果要释放所有节点,必须有一个时刻计数器为 0。在高负载的情况下,往往不会存在这样的时刻,从而导致待删除节点的列表无限增长.
Hazard Pointer(风险指针)
另一个释放的思路是,在线程访问节点时,设置一个保存了线程 ID 和该节点的风险指针。用一个全局数组保存所有线程的风险指针,释放节点时,如果数组中不存在包含该节点的风险指针,则可以直接释放,否则将节点添加到待删除列表中。风险指针实现如下
// Hazard Pointer
#include <atomic>
#include <stdexcept>
#include <thread>
static constexpr std::size_t MaxSize = 100;
struct HazardPointer {
std::atomic<std::thread::id> id;
std::atomic<void*> p;
};
static HazardPointer HazardPointers[MaxSize];
class HazardPointerHelper {
public:
HazardPointerHelper() {
for (auto& x : HazardPointers) {
std::thread::id default_id;
if (x.id.compare_exchange_strong(default_id,
std::this_thread::get_id())) {
hazard_pointer = &x; // 取一个未设置过的风险指针
break;
}
}
if (!hazard_pointer) {
throw std::runtime_error("No hazard pointers available");
}
}
~HazardPointerHelper() {
hazard_pointer->p.store(nullptr);
hazard_pointer->id.store(std::thread::id{});
}
HazardPointerHelper(const HazardPointerHelper&) = delete;
HazardPointerHelper operator=(const HazardPointerHelper&) = delete;
std::atomic<void*>& get() { return hazard_pointer->p; }
private:
HazardPointer* hazard_pointer = nullptr;
};
std::atomic<void*>& hazard_pointer_for_this_thread() {
static thread_local HazardPointerHelper t;
return t.get();
}
bool is_existing(void* p) {
for (auto& x : HazardPointers) {
if (x.p.load() == p) {
return true;
}
}
return false;
}
把风险指针应用到LockFreeStack中
// Apply Hazard Pointer in LockFreeStack
#include <atomic>
#include <functional>
#include <memory>
#include "hazard_pointer.hpp"
template <typename T>
class LockFreeStack {
public:
void push(const T& x) {
Node* t = new Node(x);
t->next = head_.load();
while (!head_.compare_exchange_weak(t->next, t)) {
}
}
std::shared_ptr<T> pop() {
std::atomic<void*>& hazard_pointer = hazard_pointer_for_this_thread();
Node* t = head_.load();
do { // 外循环确保 t 为最新的头节点,循环结束后将头节点设为下一节点
Node* t2;
do { // 循环至风险指针保存当前最新的头节点
t2 = t;
hazard_pointer.store(t);
t = head_.load();
} while (t != t2);
} while (t && !head_.compare_exchange_strong(t, t->next));
hazard_pointer.store(nullptr);
std::shared_ptr<T> res;
if (t) {
res.swap(t->v);
if (is_existing(t)) {
append_to_delete_list(new DataToDelete{t});
} else {
delete t;
}
try_delete();
}
return res;
}
private:
struct Node {
std::shared_ptr<T> v;
Node* next = nullptr;
Node(const T& x) : v(std::make_shared<T>(x)) {}
};
struct DataToDelete {
template <typename T>
DataToDelete(T* p)
: data(p), deleter([](void* p) { delete static_cast<T*>(p); }) {}
~DataToDelete() { deleter(data); }
void* data = nullptr;
std::function<void(void*)> deleter;
DataToDelete* next = nullptr;
};
private:
void append_to_delete_list(DataToDelete* t) {
t->next = to_delete_list_.load();
while (!to_delete_list_.compare_exchange_weak(t->next, t)) {
}
}
void try_delete() {
DataToDelete* cur = to_delete_list_.exchange(nullptr);
while (cur) {
DataToDelete* t = cur->next;
if (!is_existing(cur->data)) {
delete cur;
} else {
append_to_delete_list(new DataToDelete{cur});
}
cur = t;
}
}
private:
std::atomic<Node*> head_;
std::atomic<std::size_t> pop_cnt_;
std::atomic<DataToDelete*> to_delete_list_;
};
- 风险指针实现简单并达到了安全释放的目的,但每次删除节点前后都要遍历数组并原子访问内部指针来检查,增加了很多开销
- 无锁内存回收技术领域十分活跃,大公司都会申请自己的专利,风险指针包含在 IBM 提交的专利申请中,在 GPL 协议下允许免费使用
引用计数
- 另一个方案是使用引用计数记录访问每个节点的线程数量,std::shared_ptr 的操作是原子的,但要检查是否 lock-free
- 如果是,则可以用于实现 lock-free stack
Info
stdatomic_is_lock_free(&p));
// A lock-free stack with reference counting
#include <atomic>
#include <memory>
template <typename T>
class LockFreeStack {
public:
~LockFreeStack() {
while (pop()) {
}
}
void push(const T& x) {
auto t = std::make_shared<Node>(x);
t->next = std::atomic_load(&head_);
while (!std::atomic_compare_exchange_weak(&head_, &t->next, t)) {
}
}
std::shared_ptr<T> pop() {
std::shared_ptr<Node> t = std::atomic_load(&head_);
while (t && !std::atomic_compare_exchange_weak(&head_, &t, t->next)) {
}
if (t) {
std::atomic_store(&t->next, nullptr);
return t->v;
}
return nullptr;
}
private:
struct Node {
std::shared_ptr<T> v;
std::shared_ptr<Node> next;
Node(const T& x) : v(std::make_shared<T>(x)) {}
};
private:
std::shared_ptr<Node> head_;
};
- 更通用的方法是手动管理引用计数,为每个节点设置内外部两个引用计数,两者之和就是节点的引用计数,外部计数默认为 1,访问对象时递增外部计数并递减内部计数,访问结束后则不再需要外部计数,将外部计数减 2 并加到内部计数上
// sample
#include <atomic>
#include <memory>
template <typename T>
class LockFreeStack {
public:
~LockFreeStack() {
while (pop()) {
}
}
void push(const T& x) {
ReferenceCount t;
t.p = new Node(x);
t.external_cnt = 1;
t.p->next = head_.load();
while (!head_.compare_exchange_weak(t.p->next, t)) {
}
}
std::shared_ptr<T> pop() {
ReferenceCount t = head_.load();
while (true) {
increase_count(t); // 外部计数递增表示该节点正被使用
Node* p = t.p; // 因此可以安全地访问
if (!p) {
return nullptr;
}
if (head_.compare_exchange_strong(t, p->next)) {
std::shared_ptr<T> res;
res.swap(p->v);
// 将外部计数减 2 后加到内部计数,减 2 是因为,
// 节点被删除减 1,该线程无法再次访问此节点再减 1
const int cnt = t.external_cnt - 2;
if (p->inner_cnt.fetch_add(cnt) == -cnt) {
delete p; // 内外部计数和为 0
}
return res;
}
if (p->inner_cnt.fetch_sub(1) == 1) {
delete p; // 内部计数为 0
}
}
}
private:
struct Node;
struct ReferenceCount {
int external_cnt;
Node* p;
};
struct Node {
std::shared_ptr<T> v;
std::atomic<int> inner_cnt = 0;
ReferenceCount next;
Node(const T& x) : v(std::make_shared<T>(x)) {}
};
void increase_count(ReferenceCount& old_cnt) {
ReferenceCount new_cnt;
do {
new_cnt = old_cnt;
++new_cnt.external_cnt; // 访问 head_ 时递增外部计数,表示该节点正被使用
} while (!head_.compare_exchange_strong(old_cnt, new_cnt));
old_cnt.external_cnt = new_cnt.external_cnt;
}
private:
std::atomic<ReferenceCount> head_;
};
- 不指定内存序则默认使用开销最大的
std::memory_order_seq_cst,下面根据操作间的依赖关系优化为最小内存序
// sample
#include <atomic>
#include <memory>
template <typename T>
class LockFreeStack {
public:
~LockFreeStack() {
while (pop()) {
}
}
void push(const T& x) {
ReferenceCount t;
t.p = new Node(x);
t.external_cnt = 1;
// 下面比较中 release 保证之前的语句都先执行,因此 load 可以使用 relaxed
t.p->next = head_.load(std::memory_order_relaxed);
while (!head_.compare_exchange_weak(t.p->next, t, std::memory_order_release,
std::memory_order_relaxed)) {
}
}
std::shared_ptr<T> pop() {
ReferenceCount t = head_.load(std::memory_order_relaxed);
while (true) {
increase_count(t); // acquire
Node* p = t.p;
if (!p) {
return nullptr;
}
if (head_.compare_exchange_strong(t, p->next,
std::memory_order_relaxed)) {
std::shared_ptr<T> res;
res.swap(p->v);
// 将外部计数减 2 后加到内部计数,减 2 是因为,
// 节点被删除减 1,该线程无法再次访问此节点再减 1
const int cnt = t.external_cnt - 2;
// swap 要先于 delete,因此使用 release
if (p->inner_cnt.fetch_add(cnt, std::memory_order_release) == -cnt) {
delete p; // 内外部计数和为 0
}
return res;
}
if (p->inner_cnt.fetch_sub(1, std::memory_order_relaxed) == 1) {
p->inner_cnt.load(std::memory_order_acquire); // 只是用 acquire 来同步
// acquire 保证 delete 在之后执行
delete p; // 内部计数为 0
}
}
}
private:
struct Node;
struct ReferenceCount {
int external_cnt;
Node* p = nullptr;
};
struct Node {
std::shared_ptr<T> v;
std::atomic<int> inner_cnt = 0;
ReferenceCount next;
Node(const T& x) : v(std::make_shared<T>(x)) {}
};
void increase_count(ReferenceCount& old_cnt) {
ReferenceCount new_cnt;
do { // 比较失败不改变当前值,并可以继续循环,因此可以选择 relaxed
new_cnt = old_cnt;
++new_cnt.external_cnt; // 访问 head_ 时递增外部计数,表示该节点正被使用
} while (!head_.compare_exchange_strong(old_cnt, new_cnt,
std::memory_order_acquire,
std::memory_order_relaxed));
old_cnt.external_cnt = new_cnt.external_cnt;
}
private:
std::atomic<ReferenceCount> head_;
};