Masterful Memory Management
Masterful Memory Management
Overview of the Mono platform
C#为托管语言,也就是托管代码,意思是他是运行在通用语言运行(CLR)环境中的,而不是编译他到指定的操作系统中去运行。
Native and managed memory domains
Unity 有三个内存分区:
- The managed domain: 托管分区,也就是Mono使用到的那部分,这里会使用垃圾收集(GC)来自动管理
- The native domain: 原生分区,也就是内置的一些系统,如声音,贴图,物理这些,是由c++使用的。
- The external libraries:外部库,如图形:DirectX 和 OpenGL。
托管区域还有一个就是原生区和托管区之间的交互,在交互时,需要一定的内存空间来处理,这可能会对我们的游戏造成相当大的性能影响。
The statck
栈是内存中一个特殊空间,分配给小的,短生命周期的数据,这些数据会自动回收当他们离开他们所在的范围时。这些数据都存在栈的数据结构中,读取和存储的方式就是后进后出。
栈包含了我们声明的任何局部变量,并在调用函数时处理函数的加载和卸载。这些函数调用通过所谓的调用栈进行扩展和收缩。当调用栈完成当前函数时,它将跳回到调用栈上的前一点,并从他停止的地方继续。
前一个内存分配的开始总是已知的,没有理由执行任何清理操作,因为任何新的分配可以简单地覆盖旧的数据。因此,栈是相对快速和有效的。
栈一般很小,通常是MB。造成栈溢出一般都是分配空间超过栈的空间:
- 异常大的调用栈,如无限循环
- 有一个超级大的数字,越界
尽管栈的规模相对较小,但很少引起栈溢出。
The heap
堆表示所有剩余的内存空间,它用于绝大多数内存分配。当我们的需要让一个内存分配更加的持久,我们就需要分配到堆中,还有就是数据类型过大,也是需要分配到堆中。堆和栈在物理上都是在RAM中的。
在本地代码(如C++)的编写中,我们需要手动对堆内存做管理,申请了堆内存,就一定需要手动释放该内存,不然会造成内存过大或者内存泄露。
在托管代码中,对于堆内存是通过GC来自动管理。Mono在unity程序启动时,会想操作系统申请一块堆内存空间来给我们写的C#代码使用,也叫做托管堆。堆内存开始会很小,小于1MB。会随着我们在脚本中的使用增加。
Garbage collection
GC可以让我们安全使用托管内存,让一些我们不再使用的对象回收。比如我们在销毁GameObject后,GC会标记那块内存空间,且并不会立即清空该内存空间,会在内存需要时才会清空。
当申请新的内存时,如果托管内存是足够的,直接分配。反之,就会先触发GC去扫描当前在内存的所有对象,找到那些没有在使用了,并对其清空。
Mono中的GC在Unity中使用的是追踪类型,策略是标记和扫描(Mark-and-Sweep)。这个算法大致的流程如下:
- 每分配一个对象时给他一个额外字节,来存储一个标准位,这个标志位代表这该对象是否没标记。这个 标志 开始设置为
false,表示尚未标记。当GC开始时,这个标志会标记为true来表示程序仍然可以访问该对象。 - 遍历所有对象,通过标记来判断当前对象的空间是否应该被销毁。把所有未标记的对象都清空他们的空间。
- 如果
GC后空间足够给新的对象分配,就把空间给新对象。反之,则需要向操作系统申请新的托管堆内存
Memory fragmentation
所有的对象在清空内存空间时,这个清空顺序肯跟我们在申请时的顺序不同且每个对象使用的空间也不同,所以就会产生内存碎片化的问题。因为内存是连续性的,就会出现一小格空的,然后一大格被占用。这样出现小空格很难分配给新的对象。
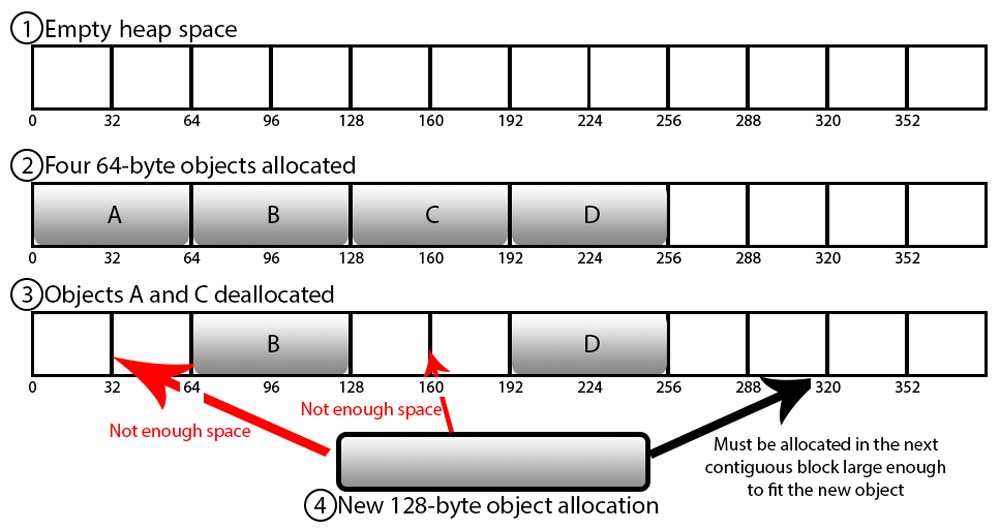
我们可以简单使用四个步骤来解释这一问题:
- 开始有一个空的堆内存空间
- 分配4格对象A,B,C,D,每个对象占用64-bytes的大小
- 过一段时间A和C释放128-bytes的空间
- 这时,我们尝试分配一个新的128-bytes大小的空间。因为A和C释放的空间并不连续,所以我们需要新申请一个空间,不能达到复用的效果。
这样的话我们就需要等到下一个申请64-bytes大小的空间或者小于时,才能对A或C的空间复用。这就会出现两个问题:
- 这造成内存复用率不高。每次都需要
GC后发现没有空间适合,就需要新的申请堆内存。 - 这会在分配新空间时,花费更多时间去找到适合的内存。
所以申请新的空间,最坏的结果会让CPU多工作很多步,如下:
- 判断当前堆内存是否有一个连续且大小合适的空间给新的对象
- 如果没有,遍历所有直接和间接的引用,将它们连接的所有内容标记为可访问
- 再次遍历这些引用,标记未标记的对象以进行释放
- 遍历所有标记的对象,检查释放其中一些对象是否会为新对象创建足够的连续空间
- 如果不能,就需要向操作系统申请新的堆内存块
- 然后分配新的空间给新对象
这对于玩家直接的影响就是游戏会卡顿,比如说一些粒子系统,角色进入一个新的场景。
Threaded garbage collection
GC一般会执行再两个线程上:
- 主线程
- 最终调用线程
这过程都不是立即释放内存空间,可能会等几秒
Code compilation
我们在写了C#代码后,它会被自动的编译到Unity编辑器下。C#并没有直接编译到机器码,不像C++一样使用静态编译器转化为机器码。
我们的代码被转化为Common Intermediate Language(CIL),它是机器码之上的抽象。属于是一种中间语言,它和Java的字节码相似,CPU并不能直接运行这个代码。
在运行是,中间代码运行在Mono的虚拟机上,虚拟机可以使同样的代码运行在不同的平台上。
在通用语言运行环境中(CLR),中间语言(CIL)是需要编译成本地代码,从而使平台的CPU能够运行编写的指令,这里由两种方式:
- Ahead-Of-Time(AOT):提前编译,构建时编译或者软件初始化时编译。所以会再运行时快一些。
- Just-In-Time(JIT):运行时在调用前,在一个独立线程中编译。所以会花一些时间编译,但是一旦编译过后的模块,后续再次调用就不需要再编译。
JIT编译必须快速,所以无法像静态的AOT编译器一样使用很多优化的方式。Mono有些平台只支持AOT而有些平台只支持JIT,可以查看这个文档:https://docs.unity3d.com/Manual/ScriptingRestrictions.html
Building a project using IL2CPP
IL2CPP是一个脚本后台,用于把Mono的CIL转化为对应平台的C++代码。这可以提高运行效率。IL2CPP提供了自带的AOT编译器和一个虚拟机,同时还可以自定义一些子系统,如GC和编译过程。
Unity选择使用IL2CPP的原因:https://blog.unity.com/technology/the-future-of-scripting-in-unity
Unity中的IL2CPP具体可以查看文档:https://docs.unity3d.com/Manual/IL2CPP.html
How to profile memory issues
Implement various memory-related performance enhancements
Minimizing garbage collection
Profiling memory consumption
使用Profiler.GetRuntimeMenorySize()可以获得本地代码分配的内存。
使用Profiler.GetMonoHeapSize()和Profiler.GetMonoUsedSize()获取托管堆中内存大小和托管代码已经使用的代码。
Profiling memory efficiency
我们衡量内存管理是否是良好时,就去观察GC的行为。GC的运行的次数越多,就会产生更多浪费和性能更加糟糕。
Garbage collection tactics
一个最小化垃圾回收问题的策略是在我们确信玩家不会注意到的时候手动调用GC来隐藏垃圾回收。可以使用System.GC.Collect()。
手动调用这个方法最好的时机,是场景切换,游戏暂停,或者是玩家不经意间。我们也可以使用Profiler.GetMonoUsedSize()和Profiler.GetMonoHeapSize()这两个方法来判断内存的使用程度,来手动调用GC。
我们也可以让在销毁后需要立即清空内存的对象继承于IDiposable,我们可以强制控制这个对象的内存清空。在Unity引擎中也有很多继承该接口的类型:NetworkConnection,UnityWebRequest,UploadHandler...
Manual JIT compilation
如果JIT编译会导致运行时性能损失,实际上可以通过反射在任何时候强制对方法进行JIT编译。例如:
var method = typeof(MyComponent).GetMethod("MethodName");
if(method != null)
{
method.MethodHandle.GetFunctionPointer();
Debug.Log("JIT compilation complete!");
}
但是反射的使用同样是很消耗性能,所以这种方式能不用就不用。除非我们已经确定说当前性能的问题就是出现在编译上。
Using value types and reference types properly
一般而言,引用类型是分配在堆上,值类型是分配在栈上。但是当一个值类型在一个引用类型内部时,比如一个数组或者一个类,这也暗示着这个类型数据过大对于栈来说,或者需要更长存在时间,所以这种情况下久会被分配到堆内中,与它拥有的引用类型绑定在一起。
在栈里,旧数据是被新数据覆盖的。并没有新创建数据,所以栈里并不需要GC。
以下有几个典型的例子:
public class TestComponent
{
void TestFunction()
{
int data = 5; // allocated on the statck
DoSomething(data);
}// integer is dealloacted from the stack here
}
public class TestComponent : MonoBehaviour
{
int _data = 5; // allocated on the heap, deallocated when the component is destroyed
void TestFunction()
{
DoSomething(data);
}
}
public class TestData
{
public int data = 5;
}
public class TestComponent
{
void TestFunction()
{
TestData dataObj = new TestData(); // allocated on the heap
DoSomething(data);
}// dataObj is not immediately deallocated here
// but it will become a candidate during the next GC sweep
}
public class TestComponent
{
private TestData _testDataObj;
void TestFunction()
{
TestData dataObj = new TestData(); // allocated on the heap
DoSomething(data);
}
void DoSomething(TestData dataObj)
{
_testDataObj = dataObj;// a new reference created!
// The referenced object will now be marked during Mark-and-Sweep
}
}
public class TestClass
{
private int[] _intArray = new int[1000];// Reference type, full of Value types
void StoreANumber(int num)
{
_intArray[0] = num; // copy a Value
}
}
Pass by value and by reference
传递引用只是复制了一个指向值,传递值是需要复制所有值。
Structs are value types
当一个数据结构比较大时,同时它传递超过5个函数时,我们需要考虑使用ref关键字来减少复制。
Arrays are reference types
当我们创建一个引用类型的数据数组时,每个数据真实的值都在堆上,数组中存的只是一个地址。
当我们创建一个值类型的数据数组时,我们只是把一个值类型的列表打包放在堆上。
Using strings responsibly
字符串是引用类型,但是特殊的是它是不能被修改的,当它被分配后。因为字符串就是字符的数组,这也暗示着他需要一个连续的内存。所以我们在改变一个字符串的值时,是在堆中新申请一个空间,然后把这空间替换到字符串上去。所以老的字符串空间就没有被引用到了,这里就会等待GC扫描到它,然后再清理。下面有一个堆字符串特殊性的例子简介:
void TestFunction()
{
string testString = "Hello";
DoSomething(testString);
Debug.Log(testString);
}
void DoSomething(string localString)
{
localString = "World";
}
这里按照引用类型来说,这里输出的是World,但是实际上这里最终输出的是Hello。这就是字符串特殊之处,因为字符串是不可修改的,当我们修改它时,需要新分配一个含有World的字符串。这个值就会替换到localString的值。Hello的字符串的引用数变成了1。testString就不会改变。所以最终的输出是Hello。
StringBuilder 是在最开始就是申请一个长的数组,这样来处理字符串就可以不需要新区申请字符串,但是如果字符串过长,超过最开始申请的数组,也是需要新申请的。
Boxing
关于装箱,值得注意的是,把值类型的变量用作引用类型,装箱仅仅是创建了一个外壳来存放这个值类型,这个外壳可以认为是引用类型。这个行为会造成堆内存分配的,所以我们需要尽量避免。
The importance of data layout
在取数据时,减少查命中失败是一个很好的优化方式,这意味着一系列的数据都在连续的内存中,这样我们在取时就会很快。这同样对GC也很有效果,因为在检测数据时,是需要遍历所有数据的,所以这样在遍历时就更快。本质上来说,我们希望大块的引用类型的数据和大块的值类型的数据分开。就算只有一个引用类型在值类型中,那么这个值类型的所有参数都需要被验证。比如说一个数据结构:
public struct MyStruct
{
int myInt;
float myFloat;
bool myBool;
string myString;
}
MyStruct [] arraryOfStructs = new MyStruct[1000];
这里我们就需要额外去检测3000次,也就是那3个基础类型。如果我们换成这样写:
int[] myInts = new int[1000];
float[] myFloats = new float[1000];
bool[] myBoolss = new bool[1000];
string[] myStrings = new string[1000];
这样的GC就会快于上一种,这里只需要扫描字符串。
Arrays from the Unity API
在unity的API中有的方法也会在堆中分配内存,比如:
GetComponents<T>(); // (T[])
Mesh.vertices; // (Vector3[])
Camera.allCameras; // (Camera[])
这些方法我们需要避免调用,最多调用一次即可。
Using InstanceIDs for dictionary keys
我们可以使用Object.GetInstanceID()这个方法来区分对象,这种方式在使用Mono时会比IL2CPP的消耗的大一些。因为Mono调用一些线程不安全的方法,同时Mono编译器不会优化循环。
foreach loops
在Unity 2018.1 的版本前使用foreach会造成大量的堆内存分配,在之后的版本就修复。这个问题的核心还是在于GetEnumerator这个方法的实现。现在还是会有堆内存的分配,不过还好,都是复用的Enumerator对于消耗来说是比较小的。全部替换为for循环也是不太好的。
Coroutines
在开启一个协成时,会分配小部分内存去启动这个协成。如果内存和GC是一个严重问题对于项目,我们就需要减少使用短周期的协成和调用StartCoroutine很多次。
Closures
关于闭包和匿名函数的区别如下例子:
System.Func<int,int> anon = (x) => {return x;};
int result = anon(5);
以上这个例子只是单纯的匿名函数,并不是闭包,这个跟正常的本地函数是一样的。
int i = 1;
System.Func<int,int> anon = (x) => {return x + i;};
int result = anon(5);
以上这个例子就是闭包了,因为在匿名函数中使用了本地变量。编译器会申明一个自定义的类来引用环境以便于可以调用i这个数据,在运行中时,在堆中创建一个对象,这个对象会传递给匿名方法。使用完了也会销毁,所以这里就会造成GC。所以我们一般不使用闭包,使用委托对象来代替。
The .NET library functions
有两个方法我们应该避免使用LINQ和regular expressions,他们的消耗都挺高的。
Object and Perfab pooling
可以有三种类型:
- C#对象
- GameObject
- Components