Concurrency
Concurrency
Hello Concurrent World
Approaches to concurrency
有两种方式实现并发:
多个进程,使用信号,套接字,文件等作为信息传递媒介。
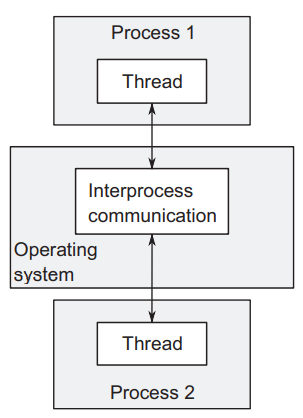
- 两个处理器之间交流比较缓慢且难开始,因为操作系统会限制一个进程突然修改另一个进程使用到的数据。
- 操作系统在开启一个进程时,消耗比较大,需要单独准备资源。
- 安全的编写并行代码。
- 通过网络连接可以在不同的物理机器上跑并行,再好的设计下,很好的提高并行度和性能。
单个处理器,多线程
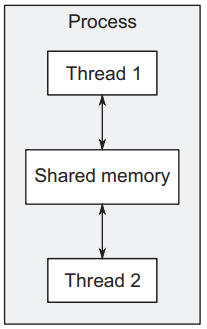
- 更小的开销
- 共享内存,交流方便
- 管理共享内存复杂
#include <iostream>
#include <thread>
void hello()
{
std::cout << "Hello Concurrent World" << std::endl;
}
int main()
{
std::thread t(hello);
t.join();
}
Managing threads
join
该方法使启动线程等启动的线程执行结束。
detach
使线程后台运行且不能在对他做join的监听工作了。
std::thread t(do_background_work);
t.detach();
assert(!t.joinable());
Passing argument
在传递传输参数时,传递的对象是会被复制的,或者传递至常引用。直接传递引用对象编译是不会通过的。
传递成员函数时,需要传递对象过去,实例如下:
class X
{
public:
void do_lengthy_work();
};
X my_x;
std::thread t(&X::do_lengthy_work,&my_x);
Transferring ownership of a thread
使用std::move()来转移线程的所有权。在被赋予新的所有权时,之前有线程任务,该任务会被终结。
Choosing the number of threads at runtime
使用std::thread::hardware_concurrency()可以获得当前硬件支持线程的数量。
使用std::this_thread:: get_id()辨别线程,如下判断是否时主线程:
std::thread::id master_thread;
void some_core_part_of_algorithm()
{
if(std::this_thread::get_id()==master_thread)
{
do_master_thread_work();
}
do_common_work();
}
Sharing data between threads
Avoiding problematic race conditions
避免资源竞争有几种方式如下:
- 以保护的机制缓存数据,只有修改数据的线程可以看到变量被修改的中间状态,访问线程只知道修改没开始或者已经完成。
- 无锁编程,修改数据结构。
- 以交易的方式来访问数据,使用中间层控制数据访问的情况。
Protecting shared data with mutexes
使用mutex来锁住数据,当一个线程锁住一个互斥变量,其他所有线程需要等待那个线程访问结束。
Using mutexes in C++
使用std::mutex声明一个互斥的变量,当需要锁住互斥值时,使用std::lock_guard创建一个警卫对象,创建这个对象时,传入互斥值,并锁定该值;在这个对象被销毁时,互斥值会被解锁。该对象是创建在栈上,所以函数结束后就会被销毁。在C++17中std::lock_guard名字被修改为std::scoped_lock
#include <list>
#include <mutex>
#include <algorithm>
std::list<int> some_list;
std::mutex some_mutex;
void add_to_list(int new_value)
{
std::lock_guard<std::mutex> guard(some_mutex);
some_list.push_back(new_value);
}
bool list_contains(int value_to_find)
{
std::lock_guard<std::mutex> guard(some_mutex);
return std::find(some_list.begin(), some_list.end(), value_to_find) != some_list.end();
}
Structuring code for protecting shared data
当使用std::lock_guard锁住互斥变量时,此时把需要保护的数据以指针或引用的方式传出,这样很大的可能不能保护数据。如以下示例代码,把需要保护的数据传出并缓存到其他地方,后续直接使用缓存的数据都会出现一定的问题。
#include <string>
#include <thread>
class some_data
{
private:
int a;
std::string b;
public:
void do_something() { std::cout << b << std::endl; }
};
class data_wrapper
{
private:
some_data data;
std::mutex m;
public:
template <typename Function>
void process_data(Function func)
{
std::lock_guard<std::mutex>(m);
// Pass "protected" data to user-supplied function
func(data);
}
};
some_data *unprotected;
void malicious_function(some_data &protected_data)
{
unexpected = &protected_data;
}
data_wrapper x;
void Run()
{
// Pass in a malicious function
x.process_data(malicious_function);
// Unprotected access to protected data
unprotected->do_something();
}
Spotting race conditions inherent in interfaces
当一个结构体内部出现了竞争,比如说操作一个栈时,多线程都在控制该数据结构,执行以下代码:
std::stack<int> some_stack;
void do_someting(int value)
{
std::cout << value << std::endl;
}
void test1()
{
if (!some_stack.empty())
{
int const value = some_stack.top();
some_stack.pop();
do_someting(value);
}
}
会出现很多顺序上的问题,比如线程A刚执行完pop()函数,但是线程B正常执行top()函数,那么线程B这里就不能获得正确的值。有以下三个基础的原则可以设置来避免这种情况:
- 把栈中的数据转存到列表中来操作。该方法最大的缺点就是在转存时,会调用复制构造函数,如果数据比较复杂,这会很消耗。
- 使用移动构造函数或者使用会抛异常的复制构造函数
- 对栈中的元素创建指针,并且对该指针进行内存管理,使用智能指针
std::shared_ptr
最终结合这三点可以编写一个线程安全的栈:
#include <exception>
#include <memory>
#include <mutex>
#include <stack>
struct empty_stack : std::exception
{
const char *what() const noexcept;
};
template <typename T>
class threadsafe_stack
{
private:
std::stack<T> data;
mutable std::mutex m;
public:
threadsafe_stack(){};
threadsafe_stack(const threadsafe_stack &other)
{
std::lock_guard<std::mutex> lock(other.m);
data = other.data;
}
threadsafe_stack &operator=(const threadsafe_stack &) = delete;
void push(T new_value)
{
std::lock_guard<std::mutex> lock(m);
data.push(new_value);
}
std::shared_ptr<T> pop()
{
std::lock_guard<std::mutex> lock(m);
// Check for empty before trying to pop value
if (data.empty())
{
throw empty_stack();
}
// Allocate return value before modifying stack
std::shared_ptr<T> const res(std::make_shared<T>(data.top()));
data.pop();
return res;
}
void pop(T &value)
{
std::lock_guard<std::mutex> lock(m);
// Check for empty before trying to pop value
if (data.empty())
{
throw empty_stack();
}
value = data.top();
data.pop();
}
bool empty() const
{
std::lock_guard<std::mutex> lock(m);
return data.empty();
}
}
除此之外,还需要注意互斥变量的个数,需要申请多个互斥变量来把锁的颗粒度变小。比如,当全局只一个互斥量时,有四个线程在运行,会出现三个线程都在等待该互斥量。可以根据数据分不同的互斥量,这样多个线程在同一时刻可以访问不同的数据。
Deadlock: the problem and a solution
当两线程A、B同时去访问一段数据时,这段数据有两个子数据data1、data2。A访问并锁住data1,B访问并锁住data2。然后A需要访问data2,B需要访问data1。这样就造成了相互等待的情况,也叫做死锁。
std::lock
std::adopt_lock: 表示一个互斥量已经被锁住,使用公用的拥有关系,并不需要再次锁定。
std::recursive_mutex