AI Fundamentals
July 1, 2025About 3 min
AI Fundamentals
What is AI Image Generation?
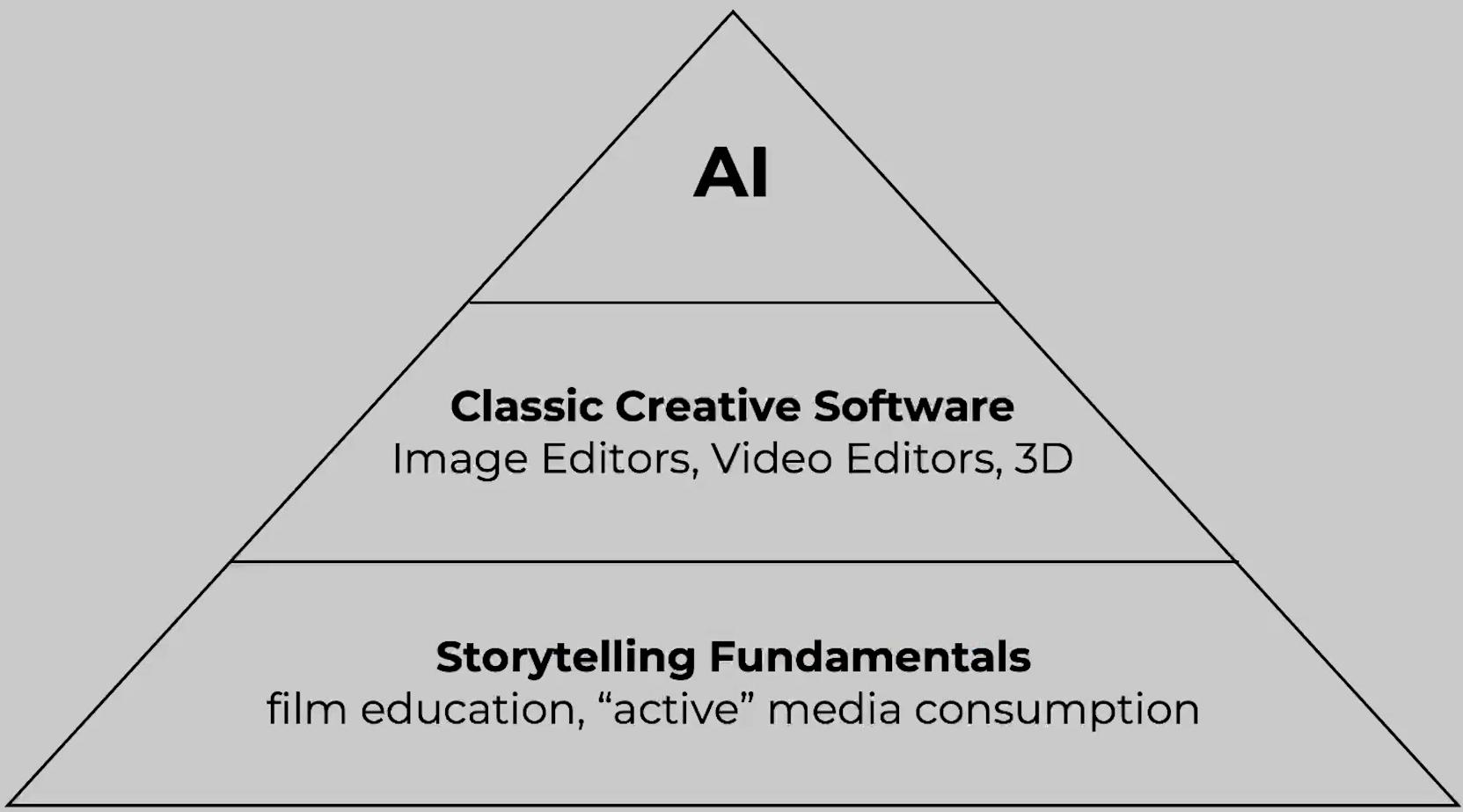
并不是一个按钮,点一下就可以生成图片
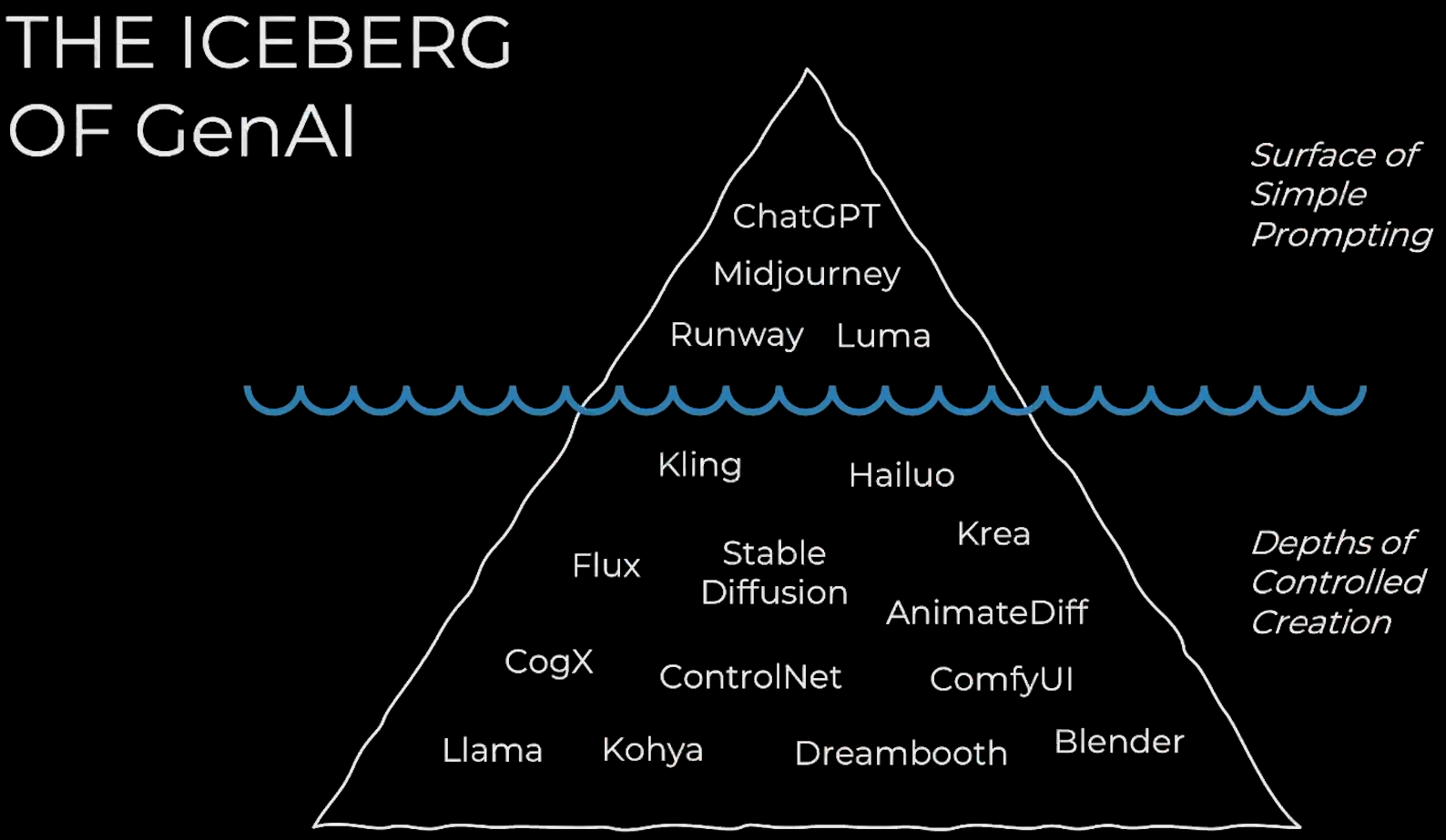
一些基础概念
- txt2img:文本生成图片
- img2img:图片生成图片
- img2vid:图片生成视频
- vid2vid:视频生成视频
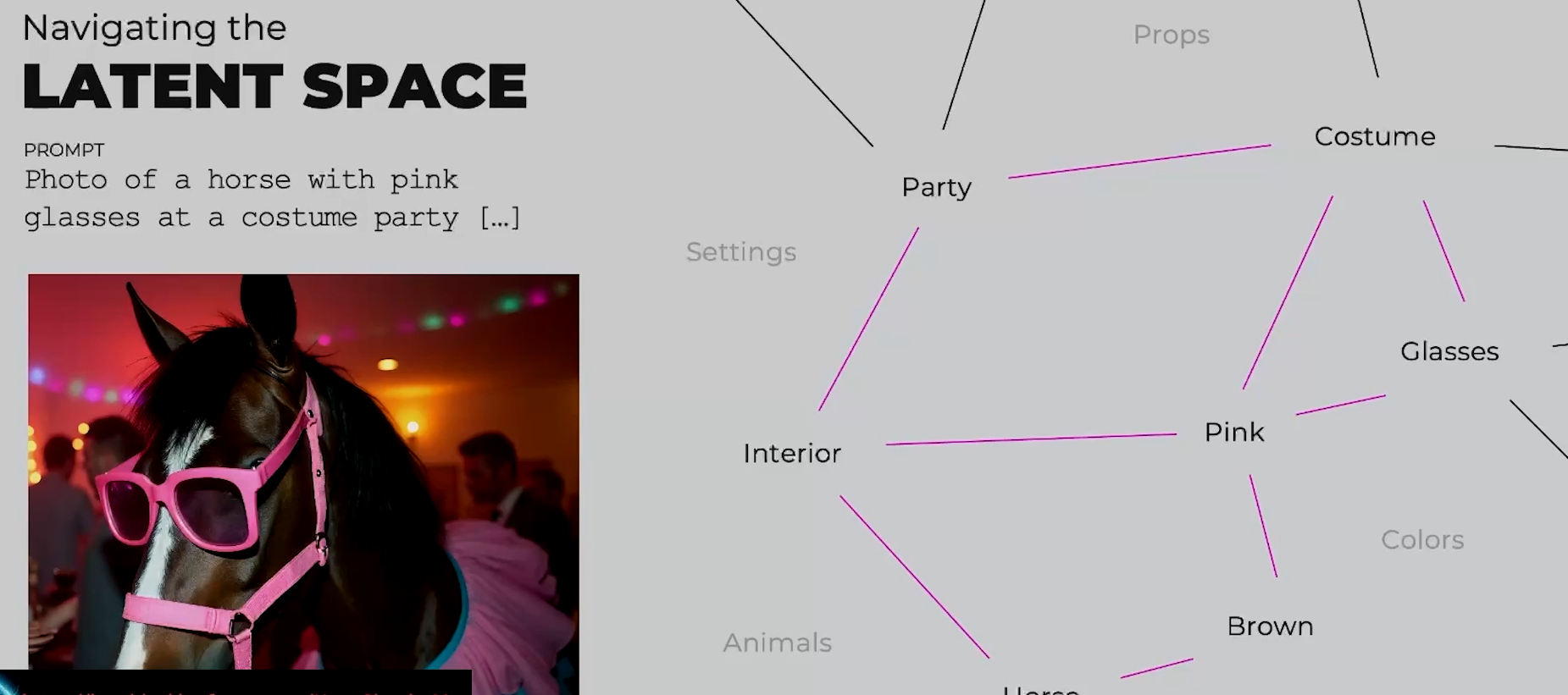
什么是Diffusion
给程序一张图片,他们能够给你一个简短的文字描述,讲述他们看到的内容。然后反向运行根据提示词去找相似标签的图片并将匹配的部分生成到最终图片上。
他们只是重新排列像素,使其看起来像给定文本。他们甚至不是拼贴机器,不把现有的图像材料拼凑在一起。
Navigating the Latent Space
AI 工具

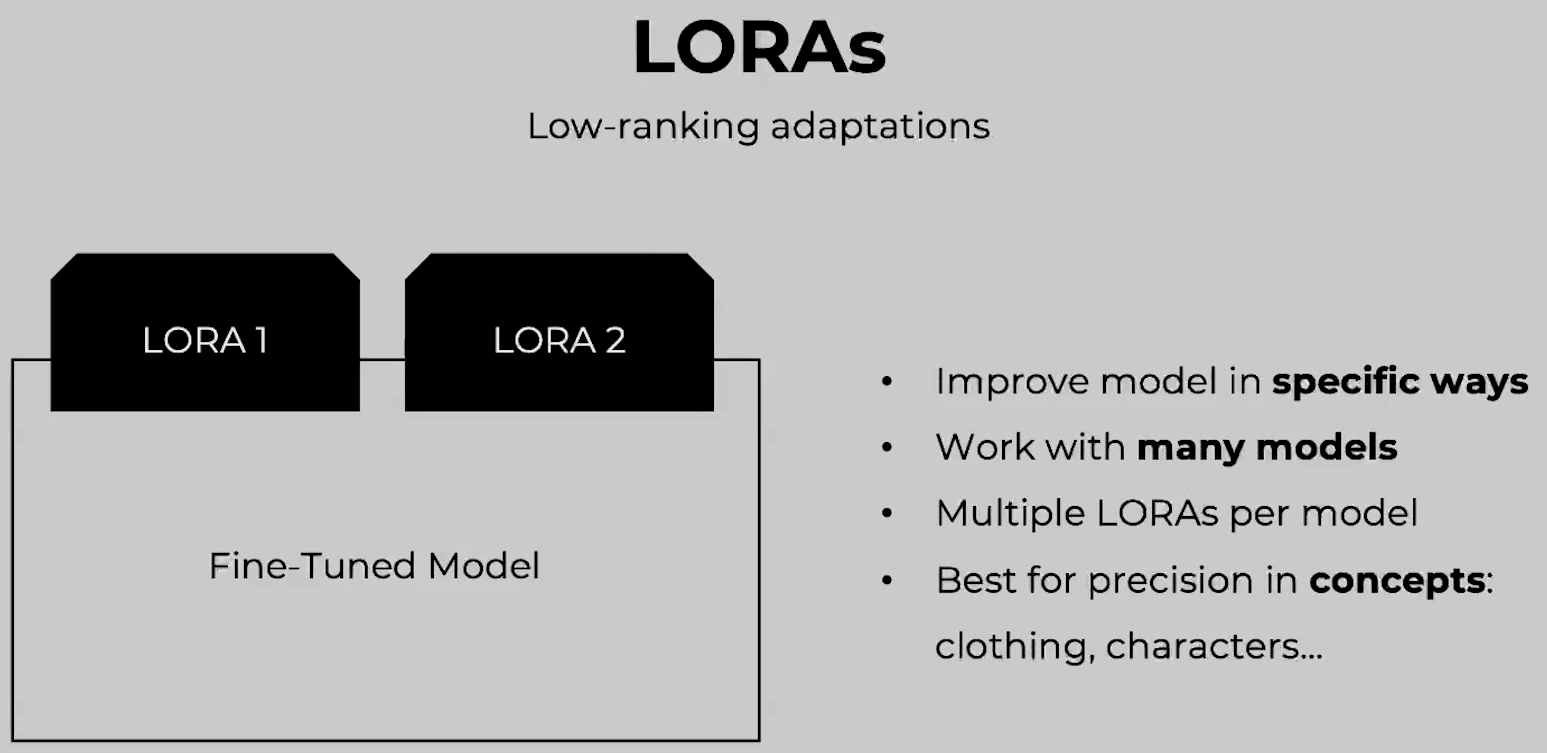
Models and Fine-Tunes

LORAS
低级别适配
Control
如何控制AI生成高质量图片:
- 给AI深度图

- 人物的姿势图,骨骼也行
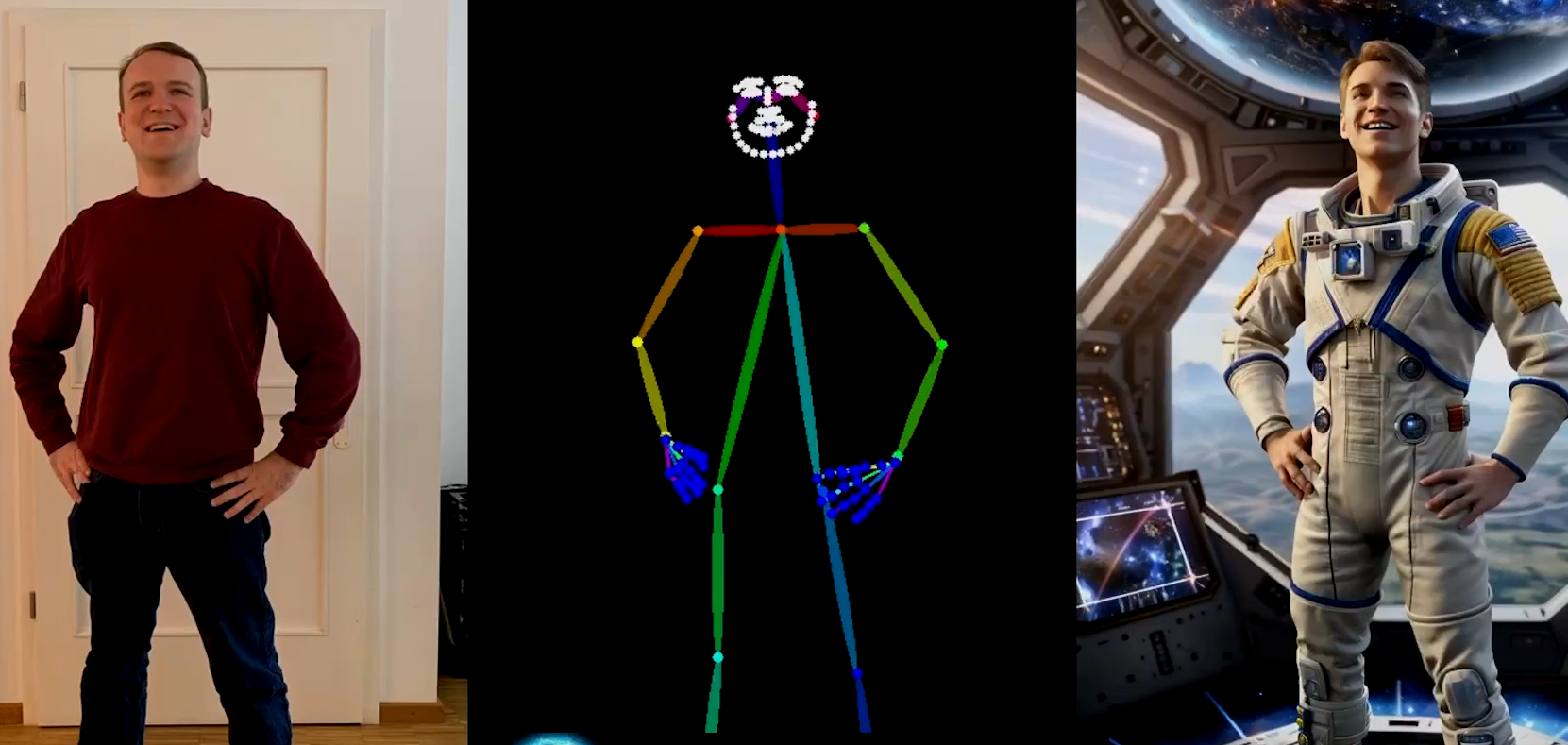
- 勾勒图

Forge
生成图片工具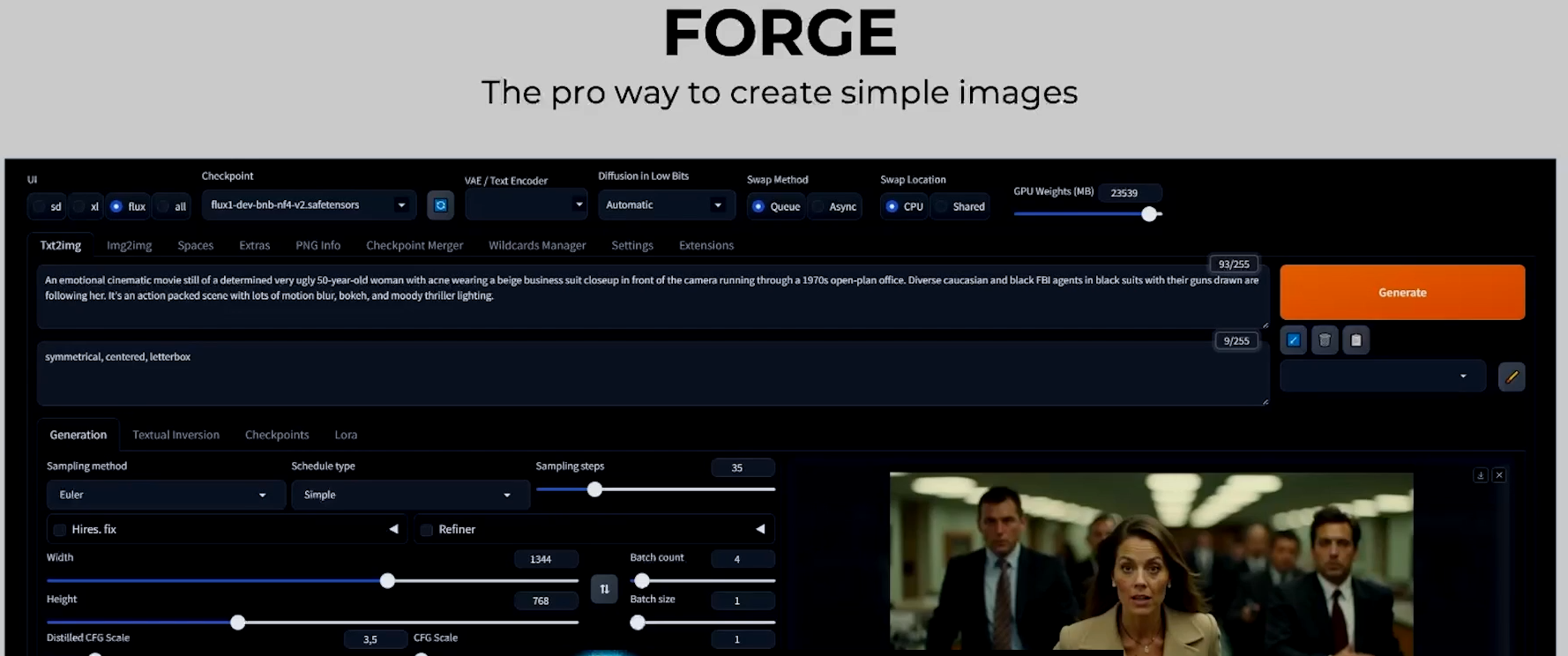
ComfyUI
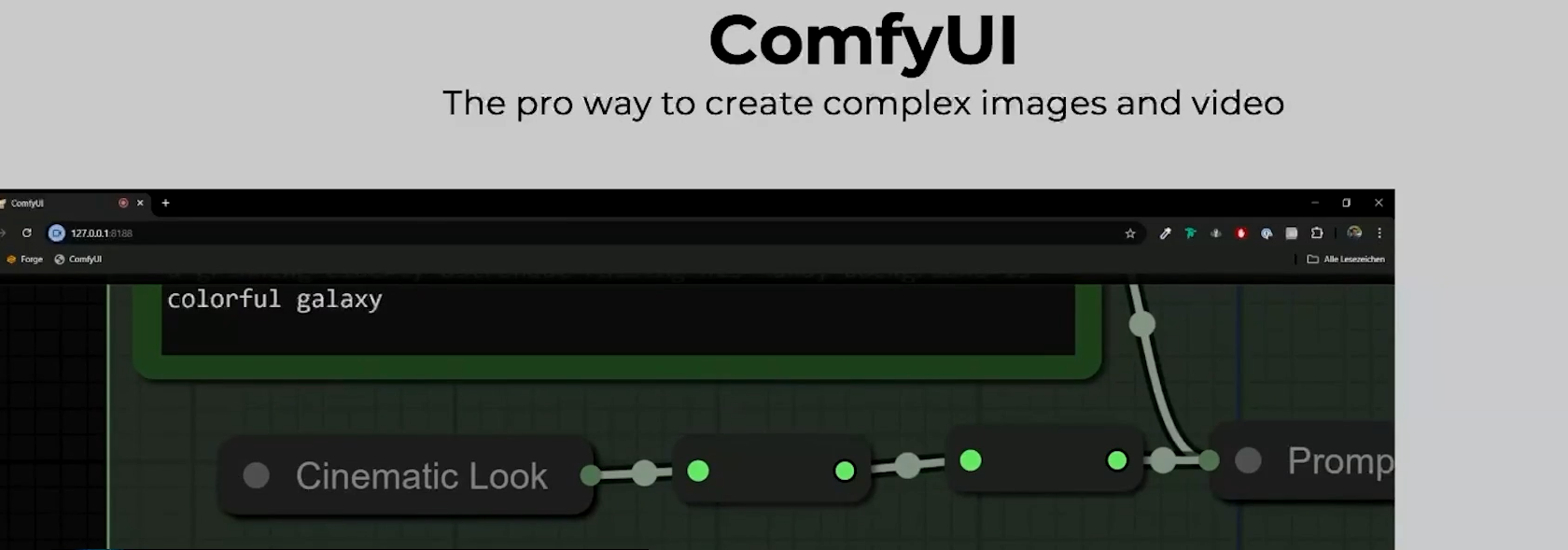
ComfyUI vs Midjourney
- 下载模型网站
- ComfyUI控制网很不错
Setting Up ComfyUI:Local
下载ComfyUI,解压后运行run_nvidia_gpu.bat
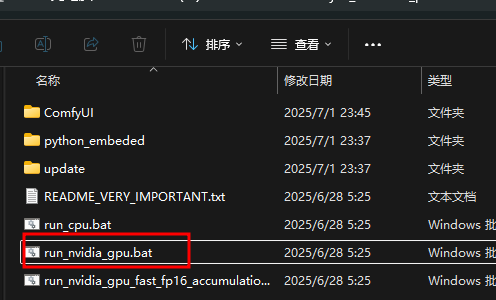
下载ComfyUI-Manager工程,解压后将文件夹复制到ComfyUI_windows_portable\ComfyUI\custom_nodes路径下即可
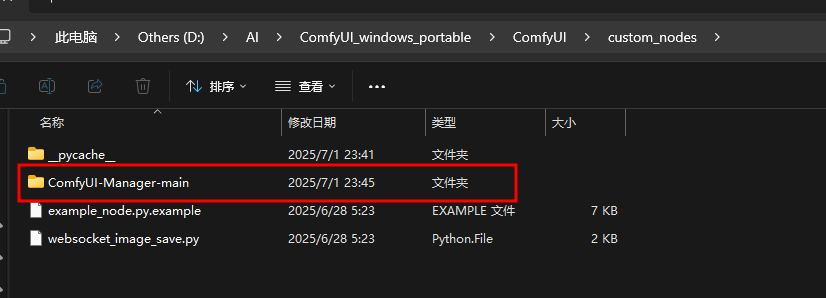
Setting Up ComfyUI: Online
Intro to Image Generation in ComfyUI
- 下载模型MOHAWK
- 将文件放在
ComfyUI\models\checkpoints目录下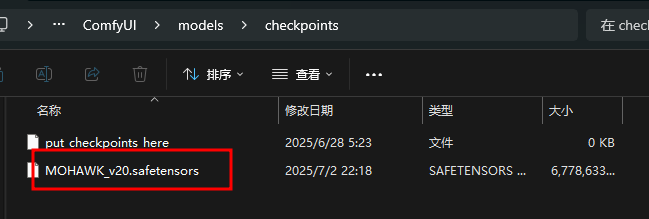
- 下载comfyui_controlnet_aux,放在路径
ComfyUI/custom_nodes/ 或者直接
或者直接Mananger->Coustom Node Mangaer安装
Node
KSampler
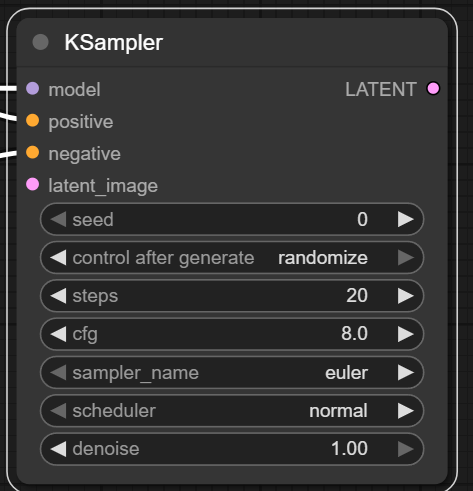
必填参数
- model:绑定一个加载的 Stable Diffusion 模型(如 stable-diffusion-v1-5.ckpt),决定生成图像的风格和能力。
- positive 和 negative: 分别输入正向提示词(希望生成的内容)和负向提示词(希望避免的内容),通常通过 CLIPTextEncode 节点编码后传入。
- latent_image:初始噪声图像(通常是空噪声或指定尺寸的潜在空间),可通过 EmptyLatentImage 节点生成。
- sampler_name: 选择采样算法,例如:
- euler(欧拉法,速度快)
- dpmpp_2m(DPM++ 二阶多步,质量高)
- ddim(确定性采样)
- lms(线性多步法)等。
- scheduler:控制噪声调度策略(如何随时间减少噪声),常见选项:
- normal(线性调度)
- karras(Karras 提出的非线性调度)
- exponential(指数调度)等。
- steps: 去噪的总步数(一般 20-30 步可平衡速度与质量,更高步数可能提升细节)。
- cfg_scale:提示词相关性系数(通常 7-12)。值越高,图像越贴合提示词,但可能过饱和;值越低,创造性越强。
- denoise:去噪强度(0.0-1.0)。1.0 表示完全重新生成,<1.0 会保留部分输入 latent 的原始信息(常用于 img2img)。
可选参数
- seed:随机种子。固定种子可复现结果,设为 0 或留空则随机生成。